卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)

4.1计算机视觉处理的对象形式
在卷积神经网络出现之前,处理图像是个难题,主要有 2 个原因:
图像需要处理的数据量太大,导致成本很高,效率很低。
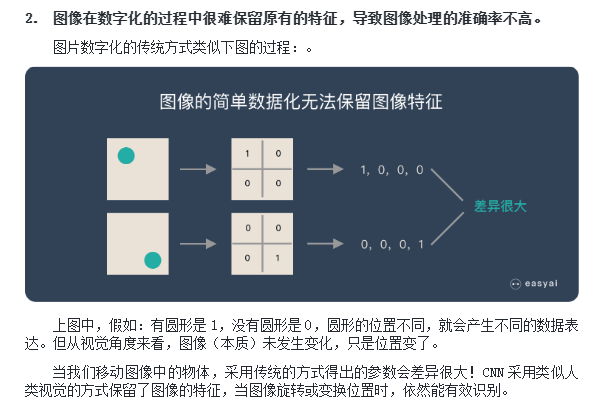
图像是由像素构成的,每个像素又是由颜色构成的。例如下图:

CNN使命就是“将复杂问题简单化”,通过卷积缩减图片的规模。
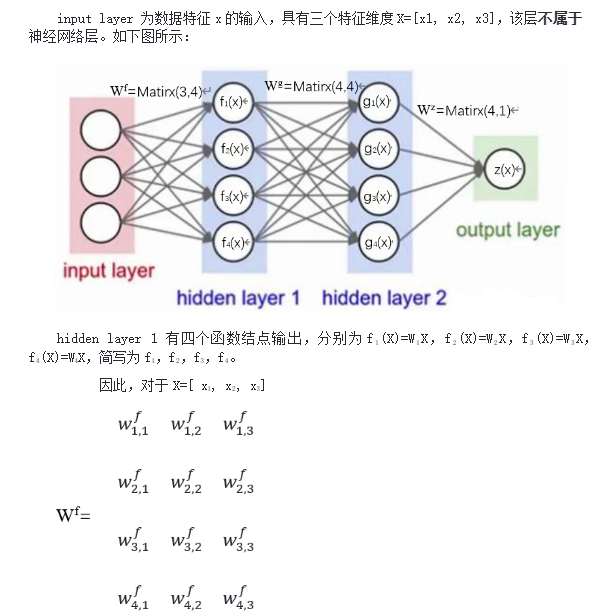
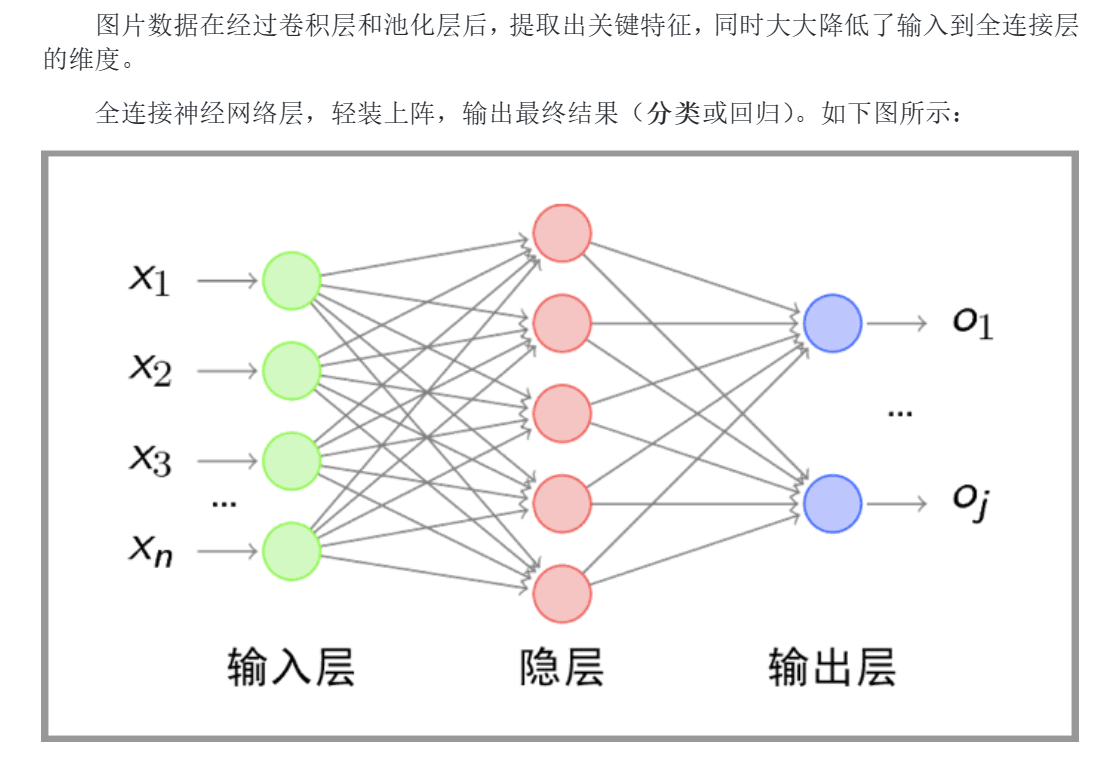
4.2全连接神经网络能否直接处理CV

4.3卷积神经网络CNN 做了什么
模仿人类大脑的这个特点,构造多层的神经网络,较低层的识别初级的图像特征,若干底层特征组成更上一层特征,最终通过多个层级的组合,最终在顶层做出分类。这就是许多深度学习算法(包括CNN) 的灵感来源。
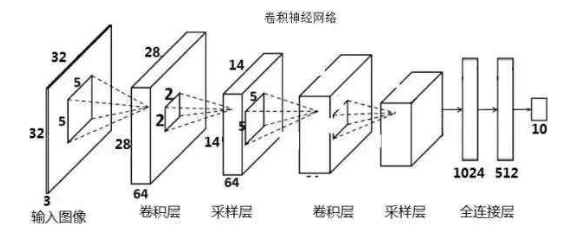
4.4 卷积神经网络的构成
TIP
卷积神经网络的创始人是着名的计算机科学家,图灵奖得主,[Yarm LeCun](杨立昆_百度百科 (baidu.com)) ,目前在Facebook 工作,他是第一个通过卷积神经网络在孤IST数据集上解决手写数字问题的人。
典型的CNN由3个部分构成:
- 卷积层《提取图像中的局部特征)
- 池化层《大幅降低数据量级,降维,或称为“降采样”)
- 全连接层《传统神经网络,输出)
4.4.1卷积神经网络源起
1993年,32岁的LeCun与他的研究团队将反向传播算法应用在卷积神经网路上,开发出了世界上第一个用于文本数字识别的卷积网络──LeNet。
LeNet后来成功商业化,被金融和邮政机构拿来读取信件或支票上的数字与条码,这不仅是LeCun在业界赚到的第一桶金,也证明了他当初与导师Hinton一同钻研的基于反向传播算法的卷积神经网路是可行的。
CNN避免了对图像的复杂前期预处理,可以直接输入原始图像进行操作,让其得到广泛的应用。从一开始能够识别手写数字,随着算力的不断发展和训练数据的不断丰富,CNN从高清图像中识别视觉出如猫和狗早已不在话下。
CNN后来在计算机视觉领域可谓是大杀四方,ImageNet竞赛一晃十载,历年来霸榜的神经网络模型如AlexNet、Inception、ResNet等等无一不是以CNN为基础架构。
而最近一年多来Transformer模型的出现以及在视觉模型上的成功应用似乎对CNN的垄断地位构成了严峻的挑战,至于是哪个模型能笑到最后,还需更多的时间来检验。
4.4.2卷积层
卷积神经网络的出现是受到了生物处理过程的启发,因为神经元之间的连接模式类似于动物的视觉皮层组织。具有五个显著的特点
局部卷积、参数共享、多核卷积、池化处理、多层处理
1.局部卷积
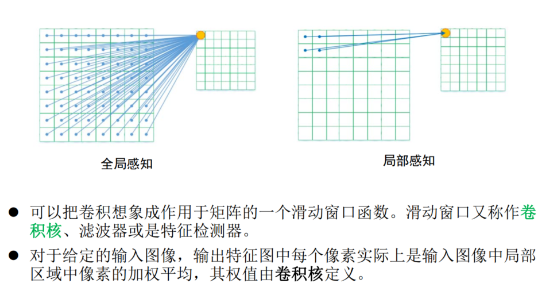
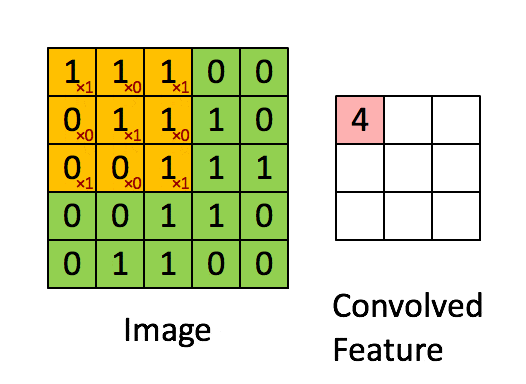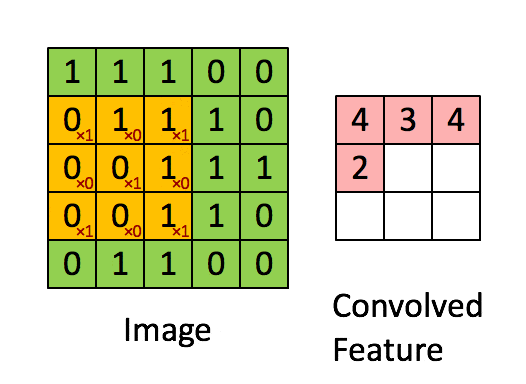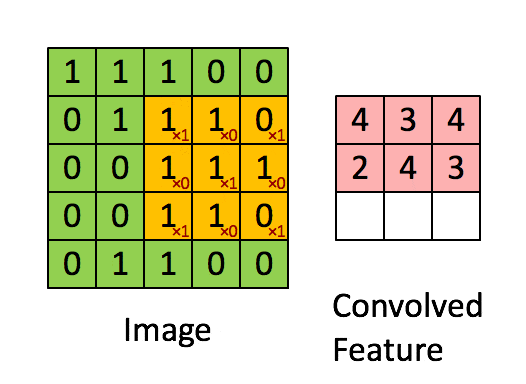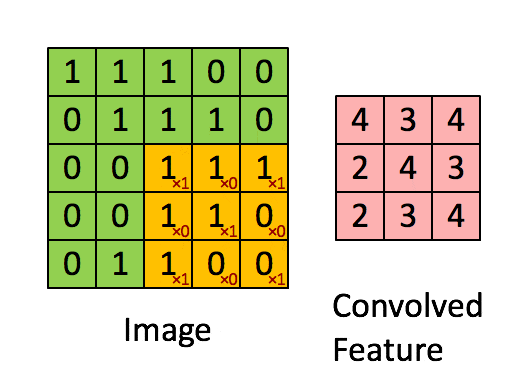
卷积层的运算过程,可以理解为使用一个过滤器(卷积核)来过滤图像的各个小区域,从而得到这些小区域的特征值。
个体皮层神经元仅在被称为感受野的视野受限区域中对刺激作出反应,不同神经元的感受野部分重叠,使得它们能够覆盖整个视野。
具体应用中,往往有多个卷积核。可以认为,每个卷积核代表了一种图像模式,如果某个图像块与此卷积核卷积出的值比较大,则认为此图像块十分 接近于此卷积核。
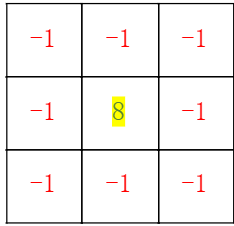
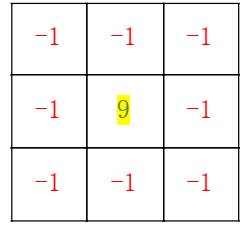
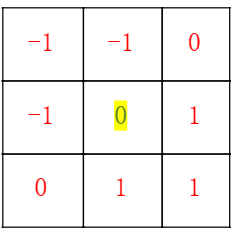
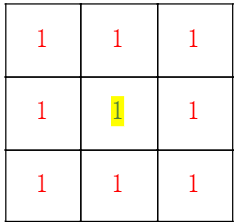
卷积核举例:
获取轮廓
锐化
浮雕
模糊
2.参数共享
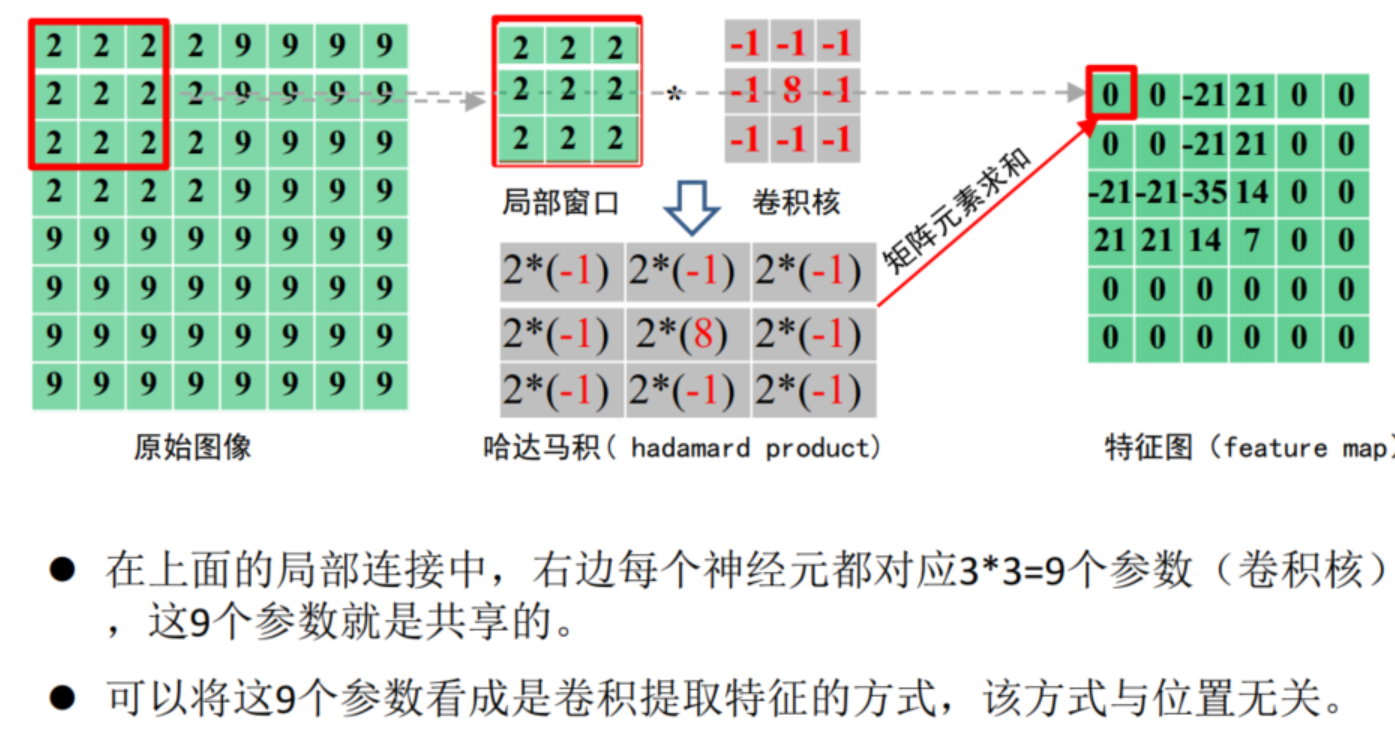
3.多核卷积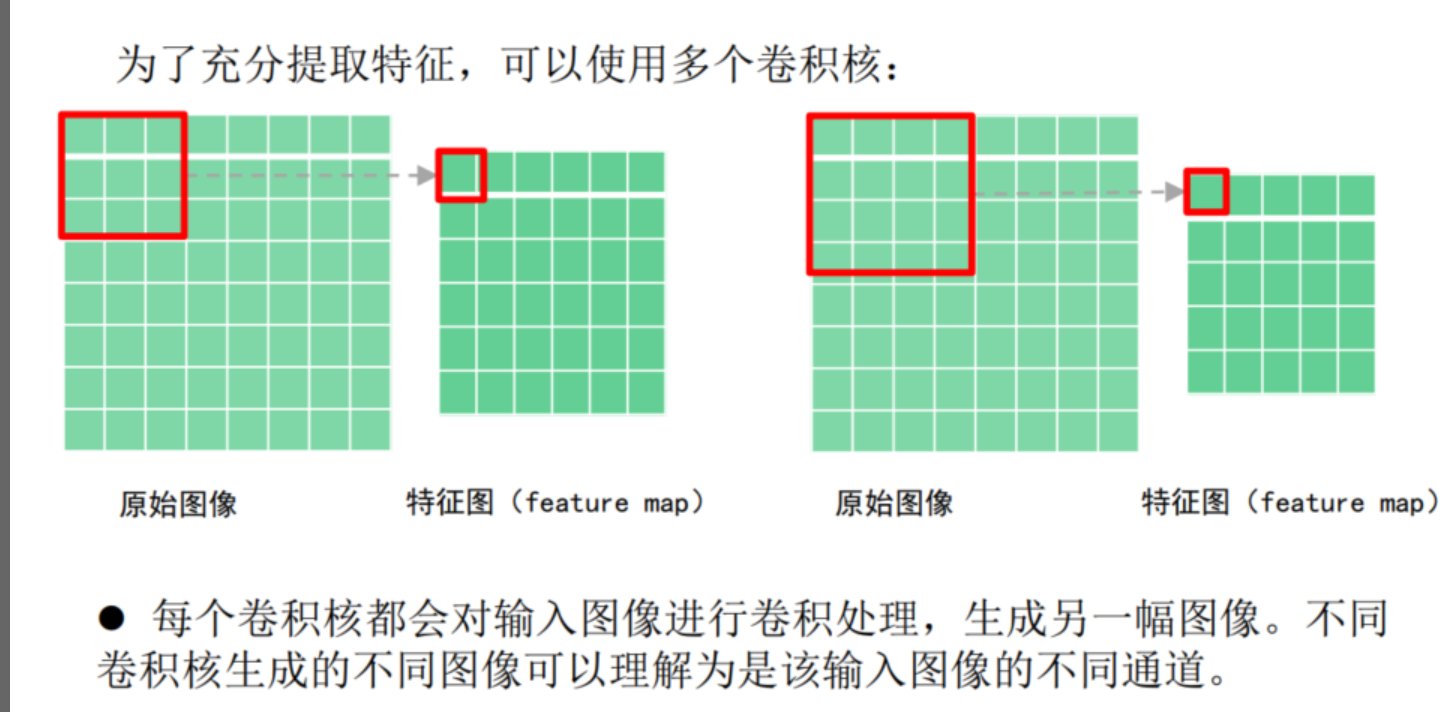
如果不对图片进行抽象特征的提取,不降维减少数据量的话,大量的图片数据在训练时就会需要更多的参数,导致模型变得更大和更臃肿,不仅导致计算成本高昂,而且速度更慢。
卷积神经网络的卷积提取特征和降维使得神经网络的参数更少,客观上也因此避免了出现过拟合现象。
4.4.3池化层
在卷积神经网络中通常会在相邻的卷积层之间加入一个池化层,从卷积提取出的众多特征中选取较为重要的 (或代表性一般特征),而不是所有已提取的特征。
通过池化层对非关键信息的滤除,可以有效缩小参数矩阵的尺寸,从而减少最后全连接层的中的参数量。
因此,加入池化层同样具有的作用:
- 可以加快计算速度。
- 防止过拟合。
4.池化处理
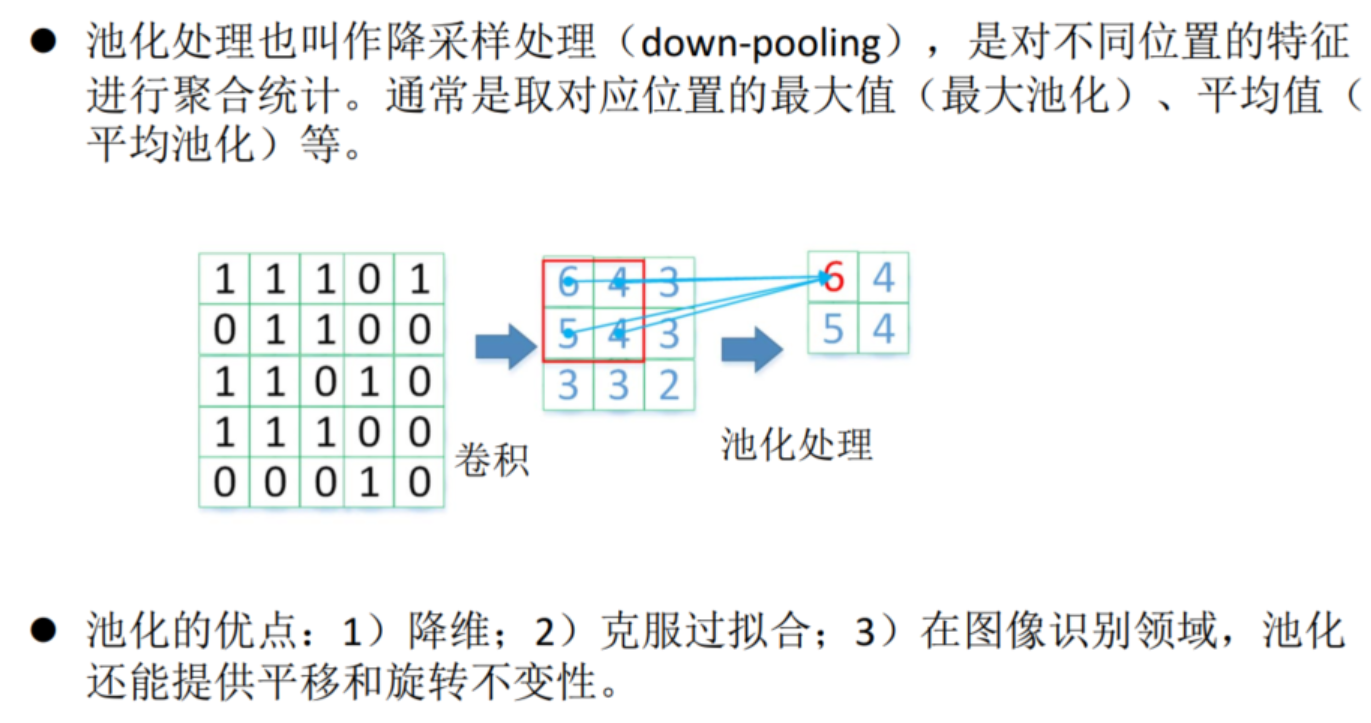
最大池化(max pooling)使用最多,其效果一般要优于平均池化(average pooling).
特征不变性
图像特征的不变性包括translation(平移),rotation(旋转),scale(尺度)等
特征降维
减少无用特征,保留主要特征。保留图像的主要特征同时就减少了模型的参数量(降维)和计算量。
防止过拟合
太细节的特征容易导致死记硬背的情况出现,对图片的抽象特征的提取,可以提高模型泛化能力。
一幅图像含有的信息量很大,特征也很多,但有些信息对于做图像任务时没有太多用途或者存在重复。将这些冗余信息(过多的细节)去除,把最 重要的特征抽取出来,就是池化操作的最大作用。
5.多层处理
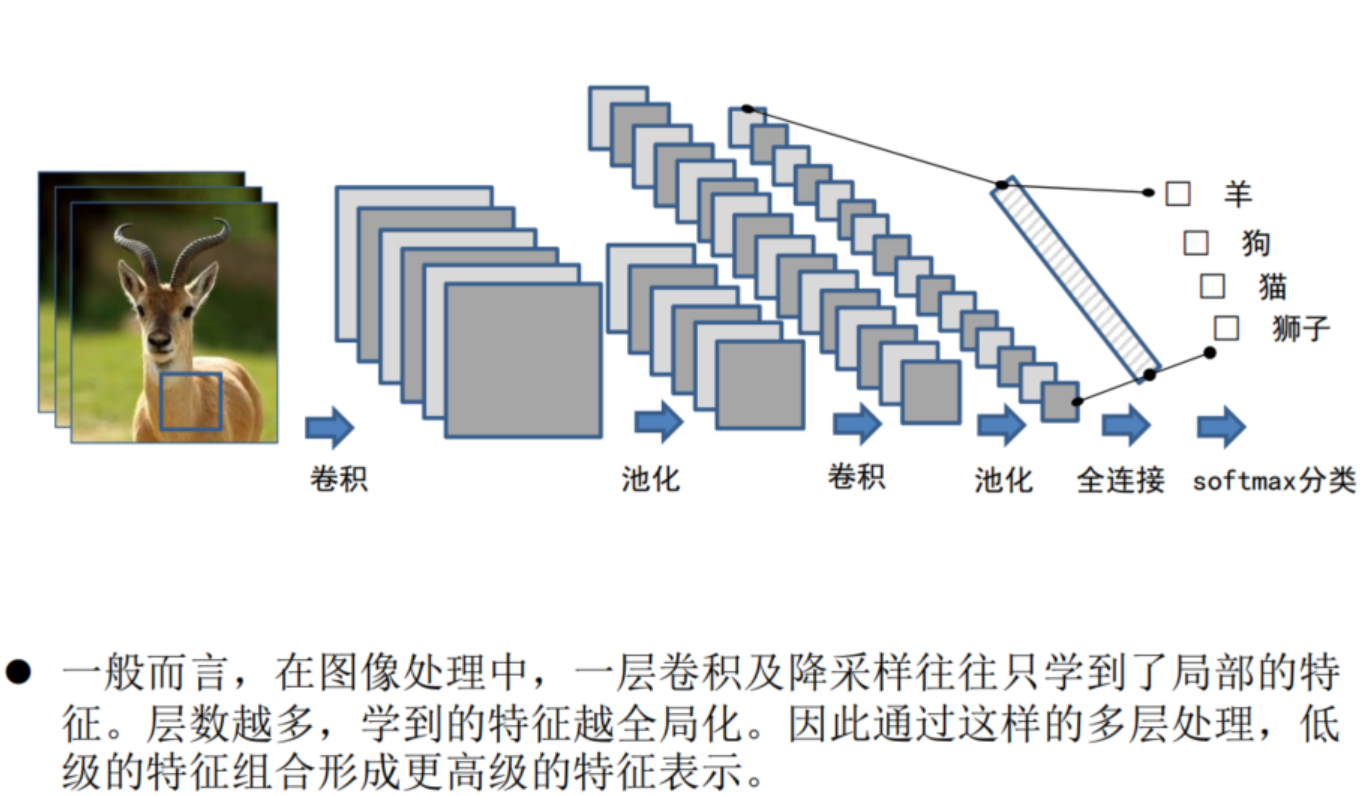
为什么要学习更深更复杂的深度学习结构?
更深的网络结构能有效减少网络的参数数量,避免维度诅咒(curse of dimensionality)大幅提高学习效率。这是因为,神经网络的不同层,往往对应不同粒度的抽象。
对于图像特征的提取,多层处理可以获得更抽象和更高级的特征表示,因此CNN通常会有多个卷积层和池化层。
4.4.4全连接层
4.5LeNet-5网络
4.6CNN的应用领域
图像分类、检索;目标定位检测;目标分割;人脸识别;骨骼识别
4.7卷积神经网络应用案例_1
4.7.1"手写数字图片" MNIST的数据预处理
import torch
from torch import nn
import torchvision
from torchvision import datasets, transforms
import numpy as np
import matplotlib.pyplot as plt
#对数据进行读取之前,通常进行预处理操作Transform。否则,读出的数据为图片对象类型<PIL.Image.Image image mode=L size=28x28>
transform = transforms.Compose( [
transforms.ToTensor(), # 将图标对象封装为张量(Tensor)格式,同时能够把灰度范围从0-255变换到0-1之间。
transforms.Normalize(mean=[0.5],std=[0.5]) #正则化 将灰度值范围从(0-1)变换到范围(-1,1) # 期望、方法
] )
train_data = datasets.MNIST(
root = "./data/",
transform=transform,
train = True,
download = True
)
test_data = datasets.MNIST(
root="./data/",
transform = transform,
train = False
)
print(len(train_data))
print(len(test_data))
train_loader = torch.utils.data.DataLoader(
train_data,
batch_size=64, #注意加载数量(批大小)
shuffle=True
)
test_loader = torch.utils.data.DataLoader(
test_data,
batch_size=64,
shuffle=True
)
#分批后,训练和测试数据各有多少批次?
print(f'训练集合包括:{len(train_loader)}批!')
print(f'训练集合包括:{len(test_loader)}批!')
data_iter = iter(train_loader)
a_batch_data = next(data_iter)
print(f'每一批数据为List类型,包括{len(a_batch_data)}个元素!')
print('a_batch_data[0].shape=', list(a_batch_data[0].shape))
# a_batch_data[0].shape= [64, 1, 28, 28]
# 64 个样本 1个通道 图片 28x28
print('a_batch_data[1].shape=', list(a_batch_data[1].shape))
# 原始数据是归一化后的数据,因此这里需要反归一化
features = a_batch_data[0][0]
# a_batch_data[0][1]中保存的是label
img = np.array(features)*255 #反归一化
print(f'img.shape={img.shape}')
img = img.reshape(28,28)
plt.imshow(img,"gray")
plt.show()4.7.2 Pytorch提供的卷积和池化
什么是特征
有效的数据、有作用的数据
图片是特征集合
卷积前后的图片
卷积前的图片-> 像素点
卷积后的图片-> 还是像素点
特征的不同形式
不同的卷积核抽取出的特征不一样(轮廓、锐化等)
好的特征
好的网络更容易得到好的特征
卷积操作
在Pytorch中,使用nn.Conv2d 类对象用于卷积操作,构造(初始化)函数的主要参数包括:
in_channels(int)为输入特征矩阵的深度(图层的通道数),即channel(通常为1 或 3 )
out_channels(int)为输出特征矩阵(特征映射图)的深度(通道数)(想得到多少种特征,可以说是有多少个卷积核)
kerner_size(int or tuple)为卷积核的尺寸,确定相邻范围
stride(int or tuple, optional)为卷积步长
padding(int or tuple, optional)是输入的每一条边补充0的层数
池化操作
池化操作的过程其实就是把输入“特征映射”(图像)划分成多个矩形区域,并从每个区域获取到一个特征值,并最终输出这些特征值到一个新的“特征映射”结果。
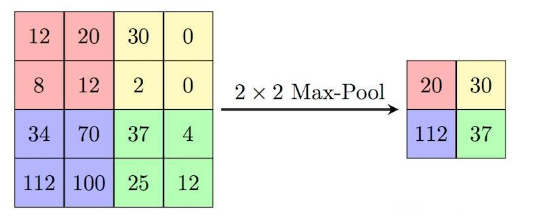
池化操作有很多种,最常见的池化操作就是最大池化和平均池化。下图所示为最大池化操作。输入图层放入了一个**最大池化 **层中,输入图层被分割成了4个区域,取每个区域内的最大值作为该区域的输出值,再把这些值排列起来,形成池化结果。
在PyTorch中,进行最大池化操作:
torch.nn.MaxPool2d(kernel_size, stride)
其中,kernel_size表示池化的窗口大小,可以是单个值,也可以是tuple元组;stride表示窗口移动步长,默认值等于kernel_size,如果设置,可以是单个值,也可以是tuple元组。
注意,如果不指定stride参数,那么默认步长 跟最大池化窗口大小kernel_size一致。如果指定了参数,那么将按照我们指定的参数进行滑动。例如stride=(2,3) ,那么窗口将每次向右滑动三个元素位置,向下滑动两个元素位置。