3.分类模型
3.1案例、乳腺癌的预测
3.1.1数据的读取与处理
3.1.1.1读取文件
加载存储介质上的数据文件,较为常见的 *.cs 文件。通常采用 pandas 包
import pandas as pd
df = pd.read_csv("./data/文件名.csv")
print(df)3.1.1.2数据集的划分
通常数据集分为:训练数据和测试数据两个部分,可利用 sklearn 中的model_selection 函数,将原数据按比例随机分为训练集数据和测试集数据.
from sklearn.model_selection import train_test_split3.1.1.3数据集的标准化
为了加快模型的收敛速度,一般都需要对原始数据进行标准化处理(将所有的数据按照比例缩放到一定范围内)。下面的例子使用sklearn.preprocessing 来对数据集合进行标准化。
其中,fit_transform(的功能是对数据进行某种统一处理,将数据缩放(映射)到某个固定区间。实现数据的标准化、归一化等等。
作用:保留特征,去除异常值
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.fit_transform(X_test)
import torch
import numpy as np
X_train = torch.from_numpy(X_train.astype(np.float32))
X_test = torch.from_numpy(X_test.astype(np.float32))
Y_train = torch.from_numpy(Y_train.astype(np.float32))
Y_test = torch.from_numpy(Y_test.astype(np.float32))
#将标记集合Y train 和Y test 转成2维
Y_train = Y_train.view(Y_train.shape[0],1)
Y_test = Y_test.view(Y_test.shape[0],1)
print(Y_train.size(),Y_test.size())3.1.2乳腺癌预测模型的定义

3.1.3乳腺癌模型的训练与预测


3.2计算机视觉基础与数据预处理
3.2.1图片的表示

3.2.2计算机视觉概述
机器视觉 (Computer Vision,CV) 是人工智能正在快速发展的一个分支。简单说来,机器视觉就是用机器代替人眼来做测量和判断。
CV 面临的挑战
- 视角变换
- 光照变化
- 尺寸变化
- 背景混淆
- 遮挡
- 同类物体的外观差异
3.2.3图像预处理
……第三章 分类模型
3.2.4模型训练的数据分批
深度学习模型进行训练时,为提升模型性能和训练的效果,通常数据集的规模都很大。
GPU擅长矩阵的并行运算,一次运算尽可能处理多的数据
但是,由于计算本身以及显存容量的限制,不可能一次性将所有数据全部加载到内存中进行计算,因此需要将训练集分批,把训练集合中的数据随机分成等量的几份(批),按批次迭代训练。
# 循环训练
for epoch in range(num_epochs):
#遍历所有批次的数据
for i_batch in range (total_batches):
# 训练过程 ……PyTorch中也为我们提供了相应的接口,可以容易地实现数据分批。 PyTorch为我们提供了torch.utils.data.DataLoader加载器,该加载器可以自动的将传入的数据进行打乱和分批。
DataLoader0的加载参数如下
- dataset:需要打乱的数据集
- batch_size:每一批数据条数
- shuffle: True或者False,表示是否将数据打乱后再分批
示例:
import pandas as pd
from torch.utils.data import DataLoader
df = pd.read_csv("data/wine.csv")
display(df)
#%%
df.columns
#%%
df.index
#%%
from torch.utils.data import Dataset
class WinDataSet(Dataset):
def __init__(self, path) -> None:
df = pd.read_csv(path)
self.n_samples = df.shape[0]
self.features = df.values[:, 1:]
self.labels = df.values[:, 0]
def __getitem__(self, index):
return self.features[index], self.labels[index]
def __len__(self):
return self.n_samples
#%%
wine_dataset = WinDataSet("./data/wine.csv")
print(wine_dataset)
print(len(wine_dataset))
print(wine_dataset.__len__())
wine_dataset.__getitem__(0)
#%%
dataLoader = DataLoader(
dataset = wine_dataset,
batch_size=15,
shuffle=True)
#%%
for i,(features, labels) in enumerate(dataLoader):
print(i,features.shape, labels.shape)3.2.5数据预处理
torchvision.transform 是一个包含了常用图像变化方法的工具包。主要用于图像的预处理,数据增强等工作。 本节将详细介绍 torchvision.transforms 中常用的数据处理函数和方法。
……
3.3二分类与多分类
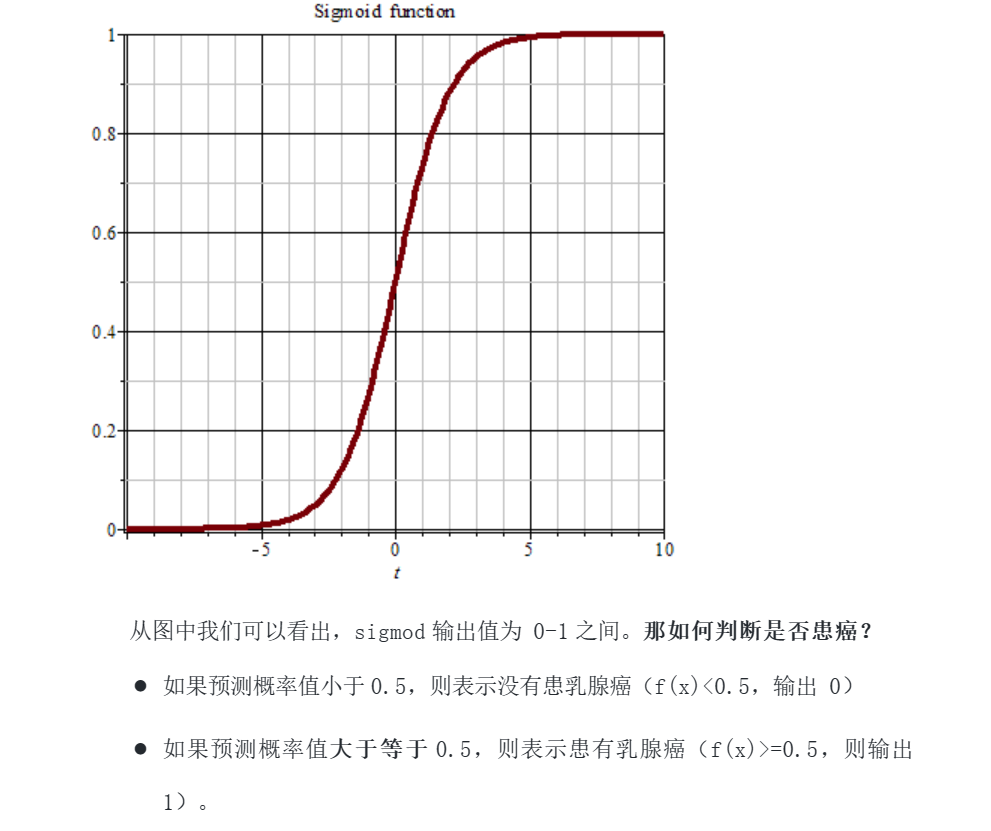
二分类问题:分类任务只有两个类别。例如想要识别一幅图是否是猫。通常会训练处一个分类器,根据输入的图像,输出该图像是猫的概率 p。对 p 进行四舍五入,输出结果为 0 或者 1,表示“不是猫”和“是猫”。这就是一个二分类问题。
多分类问题:分类任务有多个类别。例如需要建立一个分类器,可以分辨一堆水果图片中哪些是橘子、哪些是苹果、哪些是香蕉等等。 在二分类问题中,我们可以用max函数(if a > b return a else b)来判断结果,就是非黑即白。但在多分类的问题中,通常需要引入Softmax进行处理
3.3.1Softmax
在机器学习尤其是深度学习中,Softmax是个非常常用的函数,尤其在多分类的场景中使用广泛。
在多分类问题中,我们需要分类器输出每种分类的概率,且为了能够比较概率之间的大小,我们还希望概率之和能够为 1。因此,将模型对不同分类的预测值映射为 0-1之间的实数,并且通过归一化保证和为 1。
神经网络用于多分类问题时,会将输出的最后一层,加上Softmax函数,用于数据的归一化输出。 (ps:二分类通常是将Sigmod作为输出的最后一层)。

3.3.2多分类的损失函数
这里让我们介绍一种常用于多分类(包括二分类)的损失函数:交叉损失。
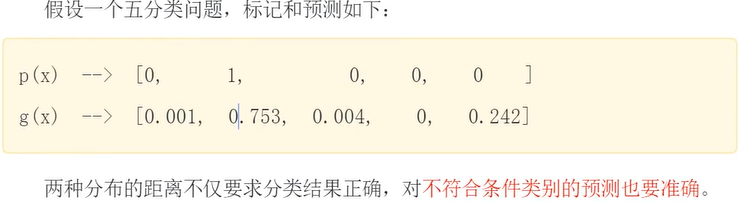
交叉熵是信息论领域的一种度量方法,它建立在熵的基础上,通常计算两种概率分布之间的差异。交叉熵损失函数经常用于分类问题中,特别是神经网络分类问题。交叉熵是用来描述两个分布的距离的,神经网络训练的目的就是使预测结果的分布 g(x) 近标记(真实)的分布 p(x)。
3.3.2.1二分类交叉熵

3.3.2.3多分类交叉熵

3.3.3采用交叉熵评估模型


3.4激活函数
通常来说,实践中大部分的分类和回归问题,简单的线性模型很难拟合
为了采用线性模型解决更为复杂的问题,模仿人类神经元组织结构增加了非线性的阑值输出。
激活函数是机器学习中很重要的概念,激活函数的加入引入了非线性因素,可以使神经网络去解决更复杂的顶测问题。
3.4.1常用激活函数
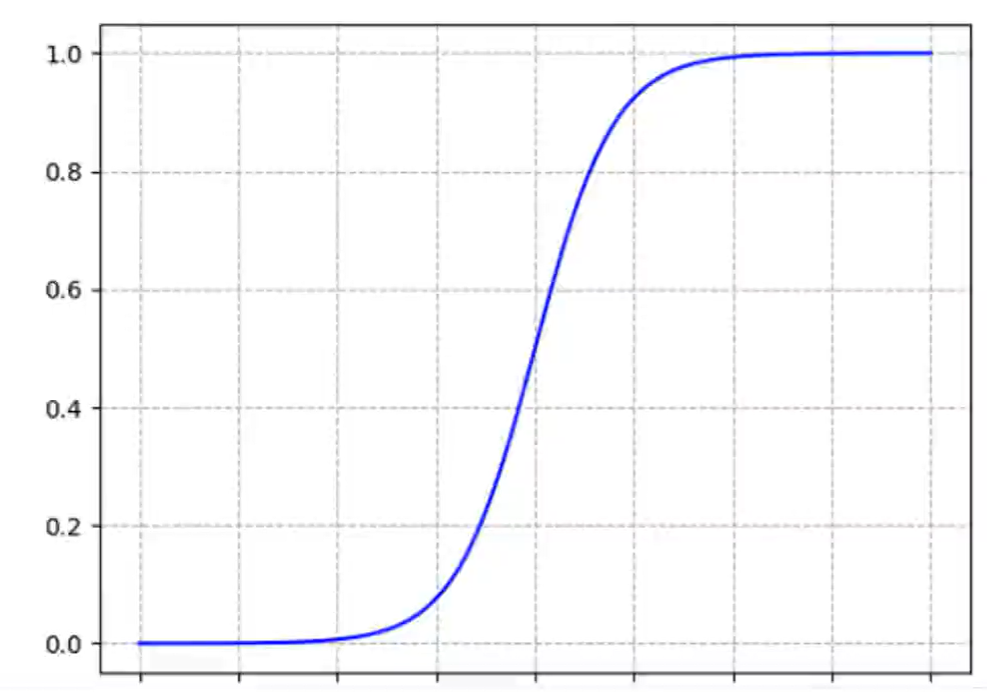
3.4.1.1Sigmod函数
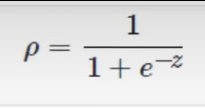
3.4.1.2Tanh函数

3.4.1.3ReLU函数

3.4.2为什么要使用激活函数
