智能云图库图片优化
一、图片查询优化
缓存
对于经常访问的数据,每次都从数据库(硬盘)中获取是比较慢,可以利用性能更高的存储来提高系统响应速度,俗称缓存。
合理使用缓存可以显著降低数据库的压力、提高系统性能。OIHLYY6Jrh0njgCHoob9feDilW1gmhwaE0THkiIV9XE=
那么,什么样的数据适合缓存呢?一般情况下就 4 个字 “读多写少”,要频繁查询的、不怎么修改的。
具体来说:
- 高频访问的数据:如系统首页、热门推荐内容等。
- 计算成本较高的数据:如复杂查询结果、大量数据的统计结果。
- 允许短时间延迟的数据:如不需要实时更新的排行榜、图片列表等。
在我们的项目中,主页是用户高频访问的内容,调用的获取图片列表的接口也是高频访问的。而且即使数据更新存在一定延迟,也不会对用户体验造成明显影响,因此非常适合缓存。
Redis 分布式缓存
分布式缓存是指将缓存数据分布存储在 多台服务器 上,以便在高并发场景下提供更高的吞吐量和更好的容错性。
Redis 是实现分布式缓存的主流方案,也是后端开发必学的技能。主要是由于它具有下面几个优势:
- 高性能:基于内存操作,访问速度极快。单节点 Redis 的读写 QPS 可达 10w 次每秒!
- 丰富的数据结构:支持字符串、列表、集合、哈希、位图等,适用于各种数据结构存储。
- 分布式支持:可以通过 Redis Cluster 构建高可用、高性能的分布式缓存,还提供哨兵集群机制提升可用性、提供分片集群机制提高可扩展性。
缓存设计
需要缓存首页的图片列表数据,也就是对 listPictureVOByPage 接口进行缓存。首先按照缓存 3 要素 “key、value、过期时间” 进行设计。
1)缓存 key 设计
由于接口支持传入不同的查询条件,对应的数据不同,因此需要将查询条件作为缓存 key 的一部分。
可以将查询条件对象转换为 JSON 字符串,但这个 JSON 会比较长,可以利用哈希算法(md5)来压缩 key。
此外,由于使用分布式缓存,可能由多个项目和业务共享,因此需要在 key 的开头拼接前缀进行隔离。设计出的 key 如下:
picture:listPictureVOByPage:${查询条件key}2)缓存 value 设计
缓存从数据库中查到的 Page 分页对象,存储为什么格式呢?这里有 2 种选择:
- 为了可读性,可以转换为 JSON 结构的字符串
- 为了压缩空间,可以存为二进制等其他结构
但是对应的 Redis 数据结构都是 string。
3)缓存过期时间设置
**必须设置缓存过期时间!**根据实际业务场景和缓存空间的大小、数据的一致性的要求设置,合适即可,此处由于查询条件较多、而且考虑到图片会持续更新,设置为 5 ~ 60 分钟即可。1GTBnr2KWjD02HAL89XX8V8KAx8IS08Lv7koMGQAUwk=
如何操作 Redis?
Java 中有非常多的 Redis 操作库,比如 Jedis、Lettuce 等。为了便于和 Spring 项目集成,Spring 还提供了 Spring Data Redis 作为操作 Redis 的更高层抽象(默认使用 Lettuce 作为底层客户端)。由于我们的项目使用 Spring Boot,也推荐使用 Spring Data Redis,开发成本更低。
它的使用也非常简单,我们直接上手项目实战。ekbamU6hmzzrytarOb9PKxI5Japd58L9vBBpEafhSBg=
后端开发
1)引入 Maven 依赖,使用 Spring Boot Starter 快速整合 Redis:
<!-- Redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>2)在 application.yml 中添加 Redis 配置:
spring:
# Redis 配置
redis:
database: 0
host: 127.0.0.1
port: 6379
timeout: 50003)编写 JUnit 单元测试文件,测试使用 StringRedisTemplate 完成对 Redis 的基础操作(增删改查):
@SpringBootTest
public class RedisStringTest {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
public void testRedisStringOperations() {
// 获取操作对象
ValueOperations<String, String> valueOps = stringRedisTemplate.opsForValue();
// Key 和 Value
String key = "testKey";
String value = "testValue";
// 1. 测试新增或更新操作
valueOps.set(key, value);
String storedValue = valueOps.get(key);
assertEquals(value, storedValue, "存储的值与预期不一致");
// 2. 测试修改操作
String updatedValue = "updatedValue";
valueOps.set(key, updatedValue);
storedValue = valueOps.get(key);
assertEquals(updatedValue, storedValue, "更新后的值与预期不一致");
// 3. 测试查询操作
storedValue = valueOps.get(key);
assertNotNull(storedValue, "查询的值为空");
assertEquals(updatedValue, storedValue, "查询的值与预期不一致");
// 4. 测试删除操作
stringRedisTemplate.delete(key);
storedValue = valueOps.get(key);
assertNull(storedValue, "删除后的值不为空");
}
}4)新写一个使用缓存的分页查询图片列表的接口。在查询数据库前先查询缓存,如果已有数据则直接返回缓存,如果没有数据则查询数据库,并且将结果设置到缓存中。
代码如下:
@PostMapping("/list/page/vo/cache")
public BaseResponse<Page<PictureVO>> listPictureVOByPageWithCache(@RequestBody PictureQueryRequest pictureQueryRequest,
HttpServletRequest request) {
long current = pictureQueryRequest.getCurrent();
long size = pictureQueryRequest.getPageSize();
// 限制爬虫
ThrowUtils.throwIf(size > 20, ErrorCode.PARAMS_ERROR);
// 普通用户默认只能查看已过审的数据
pictureQueryRequest.setReviewStatus(PictureReviewStatusEnum.PASS.getValue());
// 构建缓存 key
String queryCondition = JSONUtil.toJsonStr(pictureQueryRequest);
String hashKey = DigestUtils.md5DigestAsHex(queryCondition.getBytes());
String redisKey = "yupicture:listPictureVOByPage:" + hashKey;
// 从 Redis 缓存中查询
ValueOperations<String, String> valueOps = stringRedisTemplate.opsForValue();
String cachedValue = valueOps.get(redisKey);
if (cachedValue != null) {
// 如果缓存命中,返回结果
Page<PictureVO> cachedPage = JSONUtil.toBean(cachedValue, Page.class);
return ResultUtils.success(cachedPage);
}
// 查询数据库
Page<Picture> picturePage = pictureService.page(new Page<>(current, size),
pictureService.getQueryWrapper(pictureQueryRequest));
// 获取封装类
Page<PictureVO> pictureVOPage = pictureService.getPictureVOPage(picturePage, request);
// 存入 Redis 缓存
String cacheValue = JSONUtil.toJsonStr(pictureVOPage);
// 5 - 10 分钟随机过期,防止雪崩
int cacheExpireTime = 300 + RandomUtil.randomInt(0, 300);
valueOps.set(redisKey, cacheValue, cacheExpireTime, TimeUnit.SECONDS);
// 返回结果
return ResultUtils.success(pictureVOPage);
}测试
可以通过 Swagger 测试一下返回结果是否正常,并且对比和之前查数据库的性能提升。
没缓存,平均 50ms:
有缓存,平均 20~30 ms,性能显著提升!
细心的同学会发现,为什么接口返回的大小不一样呢?因为缓存的过程中我们将 JSON 字符串和 Java 对象进行了转换,使得一些为 null 的字段被过滤掉了。
Caffeine 本地缓存
当应用需要频繁访问某些数据时,可以将这些数据缓存到应用的内存中(比如 JVM 中);下次访问时,直接从内存读取,而不需要经过网络或其他存储系统。
相比于分布式缓存,本地缓存的速度更快,但是无法在多个服务器间共享数据、而且不方便扩容。
所以本地缓存的应用场景一般是:
- 数据访问量有限的小型数据集
- 不需要服务器间共享数据的单机应用
- 高频、低延迟的访问场景(如用户临时会话信息、短期热点数据)。
对于 Java 项目,Caffeine 是主流的本地缓存技术,拥有极高的性能和丰富的功能。比如可以精确控制缓存数量和大小、支持缓存过期、支持多种缓存淘汰策略、支持异步操作、线程安全等。
💡 建议,由于本地缓存不需要引入额外的中间件,成本更低。因此如果只是要提升数据访问性能,优先考虑本地缓存而不是分布式缓存。
缓存设计
本地缓存的设计和分布式缓存基本一致,不再赘述。但有 2 个区别:
- 本地缓存需要自己创建初始化缓存结构(可以简单理解为要自己 new 一个 HashMap)。
- 由于本地缓存本身就是服务器隔离的,而且占用服务器的内存,key 可以更精简一些,不用再添加项目前缀。
后端开发
1)参考官方文档 引入 Caffeine 的 Maven 依赖,注意如果要引入 3.x 版本的 Caffeine,Java 版本必须 >= 11!如果不想升级 JDK,也可以改为引入 2.x 版本。
<!-- 本地缓存 Caffeine -->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>3.1.8</version>
</dependency>2)构造本地缓存,设置缓存容量和过期时间:
private final Cache<String, String> LOCAL_CACHE =
Caffeine.newBuilder().initialCapacity(1024)
.maximumSize(10000L)
// 缓存 5 分钟移除
.expireAfterWrite(5L, TimeUnit.MINUTES)
.build();3)参考之前使用分布式缓存的代码,修改为使用本地缓存。在查询数据库前先查询本地缓存,如果已有数据则直接返回缓存:
// 构建缓存 key
String queryCondition = JSONUtil.toJsonStr(pictureQueryRequest);
String hashKey = DigestUtils.md5DigestAsHex(queryCondition.getBytes());
String cacheKey = "listPictureVOByPage:" + hashKey;
// 从本地缓存中查询
String cachedValue = LOCAL_CACHE.getIfPresent(cacheKey);
if (cachedValue != null) {
// 如果缓存命中,返回结果
Page<PictureVO> cachedPage = JSONUtil.toBean(cachedValue, Page.class);
return ResultUtils.success(cachedPage);
}如果没有数据则查询数据库,并且将结果设置到本地缓存中:
// 查询数据库
Page<Picture> picturePage = pictureService.page(new Page<>(current, size),
pictureService.getQueryWrapper(pictureQueryRequest));
// 获取封装类
Page<PictureVO> pictureVOPage = pictureService.getPictureVOPage(picturePage, request);
// 存入本地缓存
String cacheValue = JSONUtil.toJsonStr(pictureVOPage);
LOCAL_CACHE.put(cacheKey, cacheValue);4)可以通过 Swagger 测试一下返回结果是否正常,并且对比和之前查数据库、查 Redis 的性能提升。
有缓存,最快可达 12ms,性能又进一步提升了 1 倍左右,相比数据库提升了好几倍!
扩展
我们发现,使用本地缓存和分布式缓存的流程基本是一致的。那么思考一下,如果你想灵活地切换使用本地缓存或分布式缓存,应该怎么实现呢?U5B+YQj7OIpsUYlJ0xM2ifW28LcI7JZxuylB/f4UqCk=
答案:策略模式或者模板方法模式。
多级缓存
多级缓存是指结合本地缓存和分布式缓存的优点,在同一业务场景下构建两级缓存系统,这样可以兼顾本地缓存的高性能、以及分布式缓存的数据一致性和可靠性。OIHLYY6Jrh0njgCHoob9feDilW1gmhwaE0THkiIV9XE=
多级缓存的工作流程:
- 第一级(Caffeine 本地缓存):优先从本地缓存中读取数据。如果命中,则直接返回。
- 第二级(Redis 分布式缓存):如果本地缓存未命中,则查询 Redis 分布式缓存。如果 Redis 命中,则返回数据并更新本地缓存。
- 数据库查询:如果 Redis 也未命中,则查询数据库,并将结果写入 Redis 和本地缓存。
流程图:
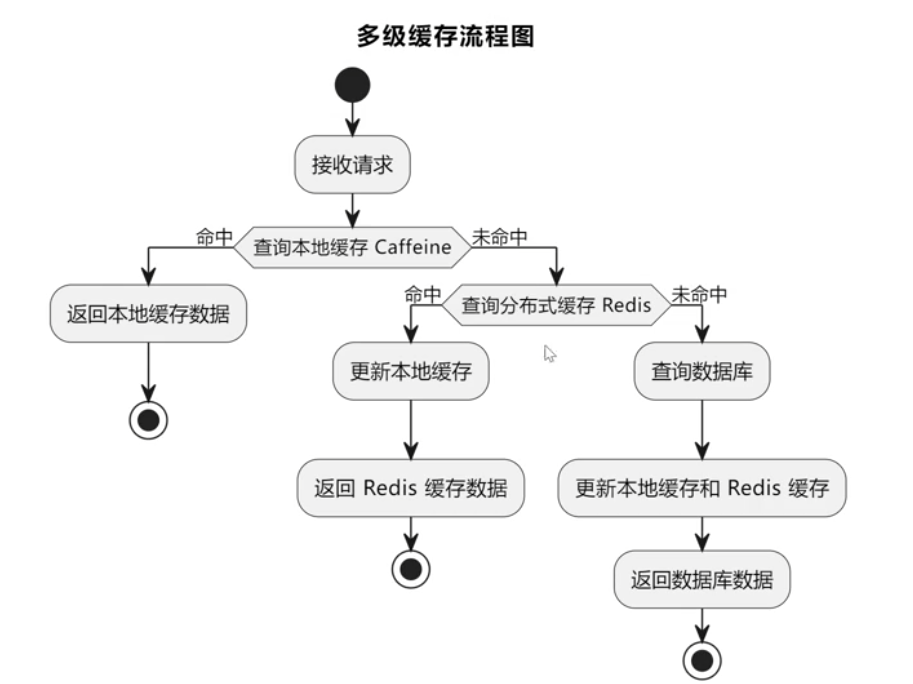
多级缓存还有一个优势,就是提升了系统的容错性。即使 Redis 出现故障,本地缓存仍可提供服务,减少对数据库的直接依赖。
后端开发
1)优先从本地缓存中读取数据。如果命中,则直接返回。
// 构建缓存 key
String queryCondition = JSONUtil.toJsonStr(pictureQueryRequest);
String hashKey = DigestUtils.md5DigestAsHex(queryCondition.getBytes());
String cacheKey = "yupicture:listPictureVOByPage:" + hashKey;
// 1. 查询本地缓存(Caffeine)
String cachedValue = LOCAL_CACHE.getIfPresent(cacheKey);
if (cachedValue != null) {
Page<PictureVO> cachedPage = JSONUtil.toBean(cachedValue, Page.class);
return ResultUtils.success(cachedPage);
}2)如果本地缓存未命中,则查询 Redis 分布式缓存。如果 Redis 命中,则返回数据并更新本地缓存。
// 2. 查询分布式缓存(Redis)
ValueOperations<String, String> valueOps = stringRedisTemplate.opsForValue();
cachedValue = valueOps.get(cacheKey);
if (cachedValue != null) {
// 如果命中 Redis,存入本地缓存并返回
LOCAL_CACHE.put(cacheKey, cachedValue);
Page<PictureVO> cachedPage = JSONUtil.toBean(cachedValue, Page.class);
return ResultUtils.success(cachedPage);
}3)如果 Redis 也未命中,则查询数据库,并将结果写入 Redis 和本地缓存。
// 3. 查询数据库
Page<Picture> picturePage = pictureService.page(new Page<>(current, size),
pictureService.getQueryWrapper(pictureQueryRequest));
Page<PictureVO> pictureVOPage = pictureService.getPictureVOPage(picturePage, request);
// 4. 更新缓存
String cacheValue = JSONUtil.toJsonStr(pictureVOPage);
// 更新本地缓存
LOCAL_CACHE.put(cacheKey, cacheValue);
// 更新 Redis 缓存,设置过期时间为 5 分钟
valueOps.set(cacheKey, cacheValue, 5, TimeUnit.MINUTES);扩展
1、手动刷新缓存
在某些情况下,数据更新较为频繁,但自动刷新缓存机制可能存在延迟,可以通过手动刷新来解决。
比如:
- 提供一个刷新缓存的接口,仅管理员可调用。
- 提供管理后台,支持管理员手动刷新指定缓存。
2、解决缓存常见问题
使用缓存时,一般要注意下面几个问题:
1)缓存击穿:某些 热点数据 在缓存过期后,大量请求直接打到数据库。
解决方案:设置热点数据的超长过期时间,或使用互斥锁(如 Redisson)控制缓存刷新。1GTBnr2KWjD02HAL89XX8V8KAx8IS08Lv7koMGQAUwk=
2)缓存穿透:用户频繁请求不存在的数据,导致大量的请求直接触发数据库查询。
解决方案:对无效查询结果也进行缓存(如设置空值缓存),或者使用布隆过滤器。
3)缓存雪崩:大量缓存同时过期,导致请求打到数据库,系统崩溃。
解决方案:设置不同缓存的过期时间,避免同时过期;或者使用多级缓存,减少对数据库的依赖。
3、自动识别热点图片缓存
可以采用热 key 探测技术,实时对图片的访问量进行统计,并自动将热点图片添加到内存缓存,以应对大量高频的访问。
4、查询优化
可以参考 数据库优化技巧,比如获取图片列表时只查询(select)必要的字段,返回给前端时也只返回必要的字段等。
5、代码优化
如果操作缓存的逻辑更复杂,可以单独抽象 CacheManager 统一管理缓存相关操作。
二、图片上传优化
图片压缩
对于图库网站来说,图片压缩是图片优化中最基本且最重要的操作,能够显著减少图片文件的大小,从而降低带宽使用和流量消耗,大幅降低成本的同时,提高图片加载速度。
有哪些压缩图片的方法呢?
- 将图片格式转换为体积更小的格式,比如 WebP 或其他现代格式
- 对图片质量进行压缩
- 缩小图片尺寸
当然对于图片网站来说,我们希望尽可能不要影响图片的质量,因此更推荐第 1 种方法。
那么将图片压缩成什么格式?如何对图片进行压缩呢?
1、图片压缩格式
格式上,有 2 种选择:
1)WebP:由 Google 开发的现代图片格式,支持有损和无损压缩。相比传统格式:
- 比 PNG 文件小约 26%。
- 比 JPEG 文件小约 25%-34%。
- 支持透明背景(Alpha 通道)。
- 兼容性:大部分主流浏览器(如 Chrome、Edge、Firefox 等)均已支持 WebP。
2)AVIF:基于 AV1 视频编码技术的图片格式,压缩率更高。
- 比 WebP 的文件大小更小,画质更优。
- 支持透明背景和高动态范围(HDR)。
虽然 AVIF 看起来更牛,但目前其兼容性没有 WebP 要好,为了保证图片在不同浏览器都能正常加载,建议选择 WebP 格式。
2、图片压缩方案
跟解析图片的操作一样,可以使用本地的图像处理类库自行操作,也可以利用第三方云服务完成。
因为我们图片已经上传到了腾讯云 COS 对象存储服务,可以直接利用数据万象服务。通过配置图片处理规则,在图片上传的同时自动进行压缩处理,减少开发成本。
如何利用数据万象对图片进行压缩呢?官方提供了 最佳实践文档 ,主要有 2 种压缩方式:访问图片时实时压缩
- 上传图片时实时压缩,参考文档
其实还有第三种方式,也可以对已上传的图片进行压缩处理,参考文档。
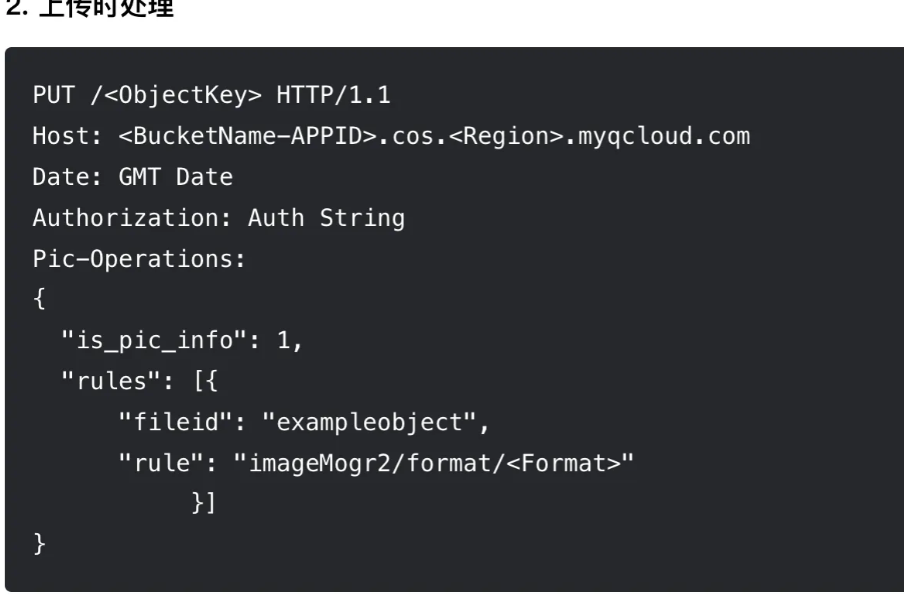
对于我们的需求,要将图片格式转化为 WebP,可以 参考官方文档,在上传文件时,传入 Rules 规则。使用 HTTP API 调用时,传入处理规则参数:
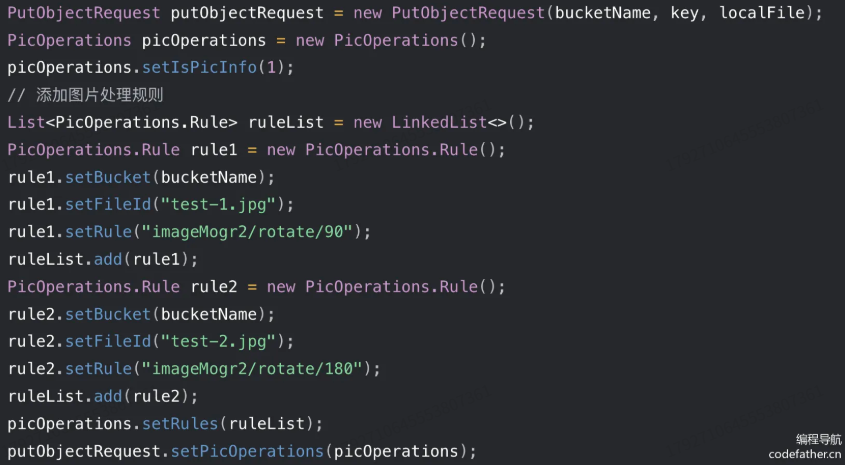
如果使用 SDK,就需要构造图片处理规则对象,参考文档:
3、后端开发
为了实现方便,我们此处仅对文件格式进行转化,不进行质量变换之类的其他处理。
1)修改 CosManager 上传图片的方法,将图片后缀转为 webp,并且使用数据万象将图片格式转为 webp:
public PutObjectResult putPictureObject(String key, File file) {
PutObjectRequest putObjectRequest = new PutObjectRequest(cosClientConfig.getBucket(), key,
file);
// 对图片进行处理(获取基本信息也被视作为一种处理)
PicOperations picOperations = new PicOperations();
// 1 表示返回原图信息
picOperations.setIsPicInfo(1);
List<PicOperations.Rule> rules = new ArrayList<>();
// 图片压缩(转成 webp 格式)
String webpKey = FileUtil.mainName(key) + ".webp";
PicOperations.Rule compressRule = new PicOperations.Rule();
compressRule.setRule("imageMogr2/format/webp");
compressRule.setBucket(cosClientConfig.getBucket());
compressRule.setFileId(webpKey);
rules.add(compressRule);
// 构造处理参数
picOperations.setRules(rules);
putObjectRequest.setPicOperations(picOperations);
return cosClient.putObject(putObjectRequest);
}2)修改 PictureUploadTemplate 上传图片的方法,从图片处理结果中获取到缩略图,并设置到返回结果中:
try {
// 创建临时文件
file = File.createTempFile(uploadPath, null);
// 处理文件来源(本地或 URL)
processFile(inputSource, file);
// 上传图片到对象存储
PutObjectResult putObjectResult = cosManager.putPictureObject(uploadPath, file);
ImageInfo imageInfo = putObjectResult.getCiUploadResult().getOriginalInfo().getImageInfo();
ProcessResults processResults = putObjectResult.getCiUploadResult().getProcessResults();
List<CIObject> objectList = processResults.getObjectList();
if (CollUtil.isNotEmpty(objectList)) {
CIObject compressedCiObject = objectList.get(0);
// 封装压缩图返回结果
return buildResult(originFilename, compressedCiObject);
}
// 封装原图返回结果
return buildResult(originFilename, file, uploadPath, imageInfo);
} catch (Exception e) {
log.error("图片上传到对象存储失败", e);
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "上传失败");
}3)编写新的封装返回结果方法,从压缩图中获取图片信息:
private UploadPictureResult buildResult(String originFilename, CIObject compressedCiObject) {
UploadPictureResult uploadPictureResult = new UploadPictureResult();
int picWidth = compressedCiObject.getWidth();
int picHeight = compressedCiObject.getHeight();
double picScale = NumberUtil.round(picWidth * 1.0 / picHeight, 2).doubleValue();
uploadPictureResult.setPicName(FileUtil.mainName(originFilename));
uploadPictureResult.setPicWidth(picWidth);
uploadPictureResult.setPicHeight(picHeight);
uploadPictureResult.setPicScale(picScale);
uploadPictureResult.setPicFormat(compressedCiObject.getFormat());
uploadPictureResult.setPicSize(compressedCiObject.getSize().longValue());
// 设置图片为压缩后的地址
uploadPictureResult.setUrl(cosClientConfig.getHost() + "/" + compressedCiObject.getKey());
return uploadPictureResult;
}4、测试
上传图片并查看对象存储中的资源大小,发现压缩效果显著。而且压缩图和原图同名,便于查找原图:
扩展
1)增加对原图的处理
目前每次上传图片实际上会保存原图和压缩图 2 个图片,原图占用的空间还是比较大的。如果想进一步优化,可以删除原图,只保留缩略图;或者在数据库中保存原图的地址,用作备份。
2)尝试更大比例的压缩,比如使用 质量变换 来处理图片。
扩展知识 - 文件秒传
由于文件秒传对于图片上传场景的作用有限,仅作为扩展知识学习即可,不必在本项目中实现。
文件秒传是一种基于文件的唯一标识(如 MD5、SHA-256)对文件内容进行快速校验,避免重复上传的方法,在大型文件传输场景下非常重要。可以提高性能、节约带宽和存储资源。
大家可能用过 XX 网盘软件,如果重复上传相同的文件 2 次,你会发现第二次的上传速度贼快!
文件秒传的实现方案
文件秒传的实现并不复杂,流程如下:
1)客户端生成文件唯一标识:上传前,通过客户端计算文件的哈希值(如 MD5、SHA-256),生成文件的唯一指纹。
2)服务端校验文件指纹:后端接收到文件指纹后,在存储中查询是否已存在相同文件。
- 若存在相同文件,则直接返回文件的存储路径。
- 若不存在相同文件,则接收并存储新文件,同时记录其指纹信息。
注意,客户端和服务端是相对的概念。因为现在我们要把文件上传到对象存储服务器,我们的后端此时就是“客户端”,对象存储服务器才是 “服务端”。
对于我们的项目,给图片表增加 md5 字段用于存储文件指纹,上传图片前增加类似的逻辑判断即可:
// 计算文件指纹
String md5 = SecureUtil.md5(file);
// 从数据库中查询已有的文件
List<Picture> pictureList = pictureService.lambdaQuery()
.eq(Picture::getMd5, md5)
.list();
// 文件已存在,秒传
if (CollUtil.isNotEmpty(pictureList)) {
// 直接复用已有文件的信息,不必重复上传文件
Picture existPicture = pictureList.get(0);
} else {
// 文件不存在,实际上传逻辑
}实际使用中的限制
我们目前的项目其实不适合使用文件秒传。一方面是对于图片场景,文件比较小、重复文件也相对较少,秒传的优化效果有限;另外一方面是本项目使用腾讯云 COS 的对象存储,只能通过唯一地址去取文件,无法完全自定义文件的存储结构、也不支持文件快捷方式的概念,因此秒传的文件地址必须使用和原文件相同的对象路径,可能导致其他的问题(比如用户 A 上传的图片地址等同于用户 B 上传的地址)。
扩展知识 - 分片上传和断点续传
对于大文件,还可以开启分片上传和断点续传,不需要自己开发,直接使用 对象存储的 SDK 就能完成。
三、图片加载优化
图片加载优化的目的是提升页面加载速度、减少带宽消耗,并改善用户体验。
本节鱼皮将从缩略图、懒加载、CDN 加速、浏览器缓存这 4 个方面进行全面优化。
缩略图
系统目前的问题:首页直接加载原图,原图文件通常比缩略图大数倍甚至数十倍,不仅导致加载时间长,还会造成大量流量浪费。
解决方案:上传图片时,同时生成一份较小尺寸的缩略图。用户浏览图片列表时加载缩略图,只有在进入详情页或下载时才加载原图。
1、实现方案
生成缩略图的方法和前面讲的 “图片压缩” 一致,可以使用本地图像处理类库,也可以利用第三方云服务完成。
此处我们依然选择数据万象服务,参考 Java SDK 文档 使用 SDK 来构造图片处理规则对象,具体的图片缩放参数可 参考文档:
2、后端开发
1)数据表 picture 新增缩略图字段:
ALTER TABLE picture
-- 添加新列
ADD COLUMN thumbnailUrl varchar(512) NULL COMMENT '缩略图 url';2)PictureMapper.xml 新增缩略图字段:
<result property="thumbnailUrl" column="thumbnailUrl" jdbcType="VARCHAR"/>
<!-- ... -->
<sql id="Base_Column_List">
id,url,thumbnailUrl,name,
introduction,category,tags,
picSize,picWidth,picHeight,
picScale,picFormat,userId,
createTime,editTime,updateTime,
isDelete
</sql>3)数据模型新增缩略图字段,包括 Picture 类、PictureVO 类、UploadPictureResult 类:
/**
* 缩略图 url
*/
private String thumbnailUrl;4)缩略图处理
首先明确我们使用的缩放规则,设置最大宽高后,对图片进行等比缩小。且如果缩略图的宽高大于原图,则不会处理。
修改 CosManager 的上传图片方法,补充对缩略图的处理:
public PutObjectResult putPictureObject(String key, File file) {
PutObjectRequest putObjectRequest = new PutObjectRequest(cosClientConfig.getBucket(), key,
file);
// 对图片进行处理(获取基本信息也被视作为一种处理)
PicOperations picOperations = new PicOperations();
// 1 表示返回原图信息
picOperations.setIsPicInfo(1);
List<PicOperations.Rule> rules = new ArrayList<>();
// 图片压缩(转成 webp 格式)
String webpKey = FileUtil.mainName(key) + ".webp";
PicOperations.Rule compressRule = new PicOperations.Rule();
compressRule.setRule("imageMogr2/format/webp");
compressRule.setBucket(cosClientConfig.getBucket());
compressRule.setFileId(webpKey);
rules.add(compressRule);
// 缩略图处理
PicOperations.Rule thumbnailRule = new PicOperations.Rule();
thumbnailRule.setBucket(cosClientConfig.getBucket());
String thumbnailKey = FileUtil.mainName(key) + "_thumbnail." + FileUtil.getSuffix(key);
thumbnailRule.setFileId(thumbnailKey);
// 缩放规则 /thumbnail/<Width>x<Height>>(如果大于原图宽高,则不处理)
thumbnailRule.setRule(String.format("imageMogr2/thumbnail/%sx%s>", 128, 128));
rules.add(thumbnailRule);
// 构造处理参数
picOperations.setRules(rules);
putObjectRequest.setPicOperations(picOperations);
return cosClient.putObject(putObjectRequest);
}修改 PictureUploadTemplate 的上传图片方法,获取到缩略图:
ProcessResults processResults = putObjectResult.getCiUploadResult().getProcessResults();
List<CIObject> objectList = processResults.getObjectList();
if (CollUtil.isNotEmpty(objectList)) {
CIObject compressedCiObject = objectList.get(0);
CIObject thumbnailCiObject = objectList.get(1);
// 封装压缩图返回结果
return buildResult(originFilename, compressedCiObject, thumbnailCiObject);
}修改 PictureUploadTemplate 封装返回结果的方法,将缩略图路径也设置到返回结果中:
private UploadPictureResult buildResult(String originFilename, CIObject compressedCiObject, CIObject thumbnailCiObject) {
UploadPictureResult uploadPictureResult = new UploadPictureResult();
// ...
// 设置缩略图
uploadPictureResult.setThumbnailUrl(cosClientConfig.getHost() + "/" + thumbnailCiObject.getKey());
return uploadPictureResult;
}需要同步修改 PictureService 的上传图片方法,补充设置缩略图字段:
// 构造要入库的图片信息
Picture picture = new Picture();
picture.setUrl(uploadPictureResult.getUrl());
picture.setThumbnailUrl(uploadPictureResult.getThumbnailUrl());
String picName = uploadPictureResult.getPicName();5)测试效果
上传大图片时,缩略图的效果显著,体积直接减小百倍!
但有个比较坑的情况,如果上传的图片本身就比较小,缩略图反而比压缩图更大,还不如不缩略!
我们可以优化 CosManager 图片上传的逻辑,仅对 > 20 KB 的图片生成缩略图:
// 缩略图处理,仅对 > 20 KB 的图片生成缩略图
if (file.length() > 2 * 1024) {
PicOperations.Rule thumbnailRule = new PicOperations.Rule();
thumbnailRule.setBucket(cosClientConfig.getBucket());
String thumbnailKey = FileUtil.mainName(key) + "_thumbnail." + FileUtil.getSuffix(key);
thumbnailRule.setFileId(thumbnailKey);
// 缩放规则 /thumbnail/<Width>x<Height>>(如果大于原图宽高,则不处理)
thumbnailRule.setRule(String.format("imageMogr2/thumbnail/%sx%s>", 128, 128));
rules.add(thumbnailRule);
}修改 PictureUploadTemplate 的逻辑,如果没有生成缩略图,则缩略图等于压缩图:
if (CollUtil.isNotEmpty(objectList)) {
CIObject compressedCiObject = objectList.get(0);
// 缩略图默认等于压缩图
CIObject thumbnailCiObject = compressedCiObject;
// 有生成缩略图,才得到缩略图
if (objectList.size() > 1) {
thumbnailCiObject = objectList.get(1);
}
// 封装压缩图返回结果
return buildResult(originFilename, compressedCiObject, thumbnailCiObject);
}3、前端开发
只需要将首页展示的图片改为优先读取缩略图即可:
<img
style="height: 180px; object-fit: cover"
:alt="picture.name"
:src="picture.thumbnailUrl ?? picture.url"
loading="lazy"
/>效果如图:
如果觉得太模糊了,还可以增大缩略图的宽高、调高需要生成缩略图的文件大小阈值,这是一个成本和用户体验上的权衡~
扩展
1)除了缩略图之外,还可以提供相对更清晰的 预览图,用于在图片详情页展示,仅在下载时才使用无损原图。
2)可以对文件名称进行更完整地校验处理,防止因为图片本身名称不规范导致的后缀丢失。
懒加载
懒加载(Lazy Loading)可以避免一次性加载所有图片,只有当资源需要显示时才进行加载。比如对于图片列表来说,仅在用户滚动到图片所在区域时才加载该图片资源。
实现方案
虽然懒加载的实现更多的是依赖前端,但后端也有一定的优化策略,比如对图片列表进行分页,每页不需要展示过多的内容。
前端如何实现懒加载呢?
1)使用 HTML5 原生的 loading="lazy" 属性。示例代码如下:
<img src="image.jpg" alt="示例图片" loading="lazy" />这种方法最简单,但是对旧版浏览器(如 IE)不兼容,而且不支持更复杂的懒加载需求(如动画或特殊事件触发)。
2)使用 JS 的 Intersection Observer,这个 API 能够检测元素是否进入视口,参考实现如下:
- 将图片的真实 src 替换为一个占位属性(如 data-src)。
- 使用 Intersection Observer 监听图片是否进入视口。
- 当图片进入视口时,将 data-src 的值赋给 src,触发加载。
<img data-src="image.jpg" alt="示例图片" class="lazy" />
<img data-src="image2.jpg" alt="示例图片" class="lazy" />
<script>
// 获取所有需要懒加载的图片
const lazyImages = document.querySelectorAll('img.lazy');
// 创建 Intersection Observer
const observer = new IntersectionObserver((entries, observer) => {
entries.forEach(entry => {
if (entry.isIntersecting) {
const img = entry.target;
// 将 data-src 的值赋给 src 属性
img.src = img.dataset.src;
img.classList.remove('lazy');
observer.unobserve(img); // 停止观察已加载的图片
}
});
});
// 观察每个图片
lazyImages.forEach(image => observer.observe(image));
</script>3)使用 JS 监听页面滚动事件实现。每次页面滚动时,判断图片是否进入可视区域;如果是,则给图片增加 src 属性,触发图片加载。
4)使用现成的组件库或类库实现,比如 lazysizes 库。
由于我们的项目已经使用了缩略图,加载的资源本来也不多,所以暂时没必要使用懒加载了。
扩展知识 - 渐进式加载
渐进式加载和懒加载技术类似,先加载低分辨率或低质量的占位资源(如模糊的图片缩略图),在用户访问或等待期间逐步加载高分辨率的完整资源,加载完成后再替换掉占位资源。ztfpl36LvUKHs6iwdOXN6yfBWzcFa87vq7VImI91Pg0=
适用于超清图片加载、用户体验要求较高的页面,在网络环境较差时,效果会更明显。
Ant Design Vue 的 Image 图片组件 支持渐进加载功能:
CDN 加速
1、什么是 CDN?
CDN(内容分发网络)是通过将图片文件分发到全球各地的节点,用户访问时从离自己最近的节点获取资源的技术,常用于文件资源或后端动态请求的网络加速,也能大幅分摊源站的压力、支持更多请求同时访问,是性能提升的利器。
💡 如果你想了解一些云服务的介绍、架构和最佳实践,多去看大公司云服务的产品文档,就能学到很多知识。
CDN 请求的核心过程如下:
- 图片文件由 源站(如 COS 对象存储、或者服务器)上传至 CDN 服务进行缓存。
- 当用户请求图片时,CDN 会根据用户的地理位置,返回离用户 最近的 CDN 节点缓存的图片资源。
- 未命中缓存的图片将从源站获取,并缓存在 CDN 节点,供后续用户访问,俗称 回源。
💡 回源的具体解释:在内容分发网络中,回源是指用户通过浏览器发送请求时,响应该请求的是源站点的服务器,而不是各节点上的缓存服务器。一般情况下,当 CDN 节点上的缓存服务器没有缓存响应的内容,或者响应的内容在源站点服务器上被修改,就会回源站去获取。
2、CDN 的优势
有同学会问了:COS 对象存储不也是存储图片的服务么?CDN 内容分发网络有啥独特的优势啊?
从这两个服务的名称中,我们就能明显感受到区别了,COS 更倾向于 “存储”,CDN 更倾向于 “网络请求”。
所以如果文件存储容量较大、但是访问频率较低,用对象存储性价比更高;但如果资源访问频率高、流量消耗大,还需要对访问进行加速、减少源站压力,就要使用 CDN 了。CDN 的流量和请求单价通常低于对象存储,而且更加安全,可以保护源站地址不被泄露。
3、如何使用 CDN?
一般情况下,如果你要对外提供文件(图片)访问 / 下载服务,建议结合 COS 和 CDN。比如对于本项目,COS 作为源站,负责存储图片文件;CDN 负责提供文件访问服务,以及缓存、安全性的设置。
也就是说,使用 CDN 之后,我们数据库中存储的图片地址就不再是 COS 的地址,而是 CDN 的 URL。
如何开通和使用 CDN 服务?建议阅读 官方的产品文档、还有 CDN 结合 COS 的文档,写得很贴心。
💡 CDN 还提供自动图片优化功能,感兴趣的同学可以 看文档 了解下。
但是,注意 CDN 是个付费产品,按量计费,所以使用时有一些注意事项。俗话说得好(鱼皮说的):“乱用 CDN,钱包两行泪!”
大家一定要认真看:
1)缓存策略:为静态资源(如图片、CSS、JS)设置长期缓存时间,可以减少回源的次数和消耗。
2)防盗链:配置 Referer 防盗链保护资源,比如仅允许自己的域名可以加载图片
3)IP 限制:根据需要配置 IP 黑白名单,限制不必要的访问。
4)HTTPS 配置:配置有效的 SSL 证书,启用 HTTPS 传输,提高请求的安全性。
5)**监控告警:这点尤为重要!**一定要给 CDN 配置监控告警,比如设置一段时间内最多消耗的流量,超出时会自动发短信告警,避免费用超额;或者限制单个 IP 的请求频率,防止突发流量影响服务。
6)CDN 节点选择:国内业务选择覆盖中国大陆的节点就足够了,非必要的话,不要开通全球 CDN 节点,容易遭受海外攻击。
7)访问日志:开启访问日志,分析用户行为和流量来源,这个能力更适合业务访问量较大的场景。
浏览器缓存
通过设置 HTTP 头信息(如 Cache-Control),可以让用户的浏览器将资源缓存在本地。在用户再次访问同样的资源时,直接从本地缓存加载资源,而无需再次请求服务器。
所有缓存在使用时的注意事项基本都是类似的:
1)设置合理的缓存时间。常用的几种设置参数是:
- 静态资源使用长期缓存,比如:
Cache-Control: public, max-age=31536000表示缓存一年,适合存储图片等静态资源。 - 动态内容使用验证缓存,比如:
Cache-Control: private, no-cache表示缓存可被客户端存储,但每次使用前需要与服务器验证有效性。适合会动态变化内容的页面,比如用户个人中心。 - 敏感内容禁用缓存,比如:
Cache-Control: no-store表示不允许任何形式的缓存,适合安全性较高的场景,比如登录页面、支付页面。
2)要能够及时更新缓存。可以给图片的名称添加 “版本号”(如文件名中包含 hash 值),这样哪怕上传相同的图片,由于版本号不同,得到的图片地址也不同,下次访问时就会重新加载。
对于我们的项目,图片资源是非常适合长期缓存在浏览器本地的,也已经通过给文件名添加日期和随机数防止了重复。由于图片是从对象存储云服务加载的,如果需要使用缓存,可以接入 CDN 服务,直接在云服务的控制台配置缓存,参考文档。
如果触发了浏览器本地缓存,在 F12 控制台中能够看到图片瞬间加载成功:
四、图片存储优化
数据沉降
大部分数据的访问热度会随着存储时间延长逐渐降低,为了严格控制存储成本,需要定期分析业务数据的访问情况,并动态调整存储类型。
这就涉及到 数据沉降 技术,将长时间未访问的数据自动迁移到低频访问存储,从而降低存储成本。就跟我们平时使用电脑一样,SSD 硬盘很贵,我们一般优先将常用软件放在 SSD 目录中,至于一些以前写过的资料什么的,可以放在机械硬盘或外接硬盘中。
一般情况下,数据沉降分为 2 个阶段:先分析再沉降。
1)先分析:通过对象存储提供的清单 / 访问日志分析,或者业务代码中自行统计分析。
2)再沉降:可以直接通过对象存储提供的 生命周期 功能自动沉降数据,只需编写沉降规则即可。如下图,将 30 天未修改的文件沉降至低频存储:
低频存储的价格比标准存储低了一些,还可以将 几乎不需要修改和访问 的文件(比如日志文件)移动到归档存储中,存储价格更低,可节约几倍的成本!
不过要注意,虽然低频存储的存储费用更低,但是当你要访问低频存储的资源时,会产生数据取回费用,所以一般只对几乎不访问的资源进行沉降,尽量减少取回费用。
数据沉降和 冷热数据分离 的概念是比较接近的,冷热数据分离是根据数据的访问热度,将访问频繁的数据(热数据)和访问较少的数据(冷数据)存储在不同的存储层中。
对于我们的项目,很久无人问津的历史图片就可以称为 “冷数据”,可以利用 COS 的生命周期功能在 30 天后自动沉降为低频存储。当然也可以通过数据库记录图片的访问和下载时间,自行调用 API 批量沉降数据或者转储到其他存储服务。
💡 数据沉降和冷热数据分离的概念又有一些细微的差别,个人的理解是数据沉降更倾向于关注一个对象的生命周期(一个资源从热到冷),目标更多的是降低存储成本,配置沉降规则后也一般不会调整。冷热数据分离更关注整个系统的资源分布(比如热门图片放到性能更高的硬盘中,冷门图片进行归档存储),目标是同时优化性能和节约成本,数据的热度可以实时调整。
清理策略
对于 “重存储” 的系统,数据清理是必要的!通过设置合理的清理策略,可以避免冗余数据占用存储空间,降低成本。
这里分享 4 种典型的清理策略:
1)立即清理:在删除图片记录时,立即关联删除对象存储中已上传的图片文件,确保数据库记录与存储文件保持一致。
这里还有个小技巧,可以使用异步清理降低对删除操作性能的影响,并且记录一些日志,避免删除失败的情况。
2)手动清理:由管理员手动触发清理任务,可以筛选要清理的数据,按需选择需要清理的文件范围。
3)定期清理:通过定时任务自动触发清理操作。系统预先设置规则(如文件未访问时间超过一定期限)自动清理不需要的数据。
4)惰性清理:清理任务不会主动执行,而是等到资源需求增加(存储空间不足)或触发特定操作时才清理,适合存储空间紧张但清理任务优先级较低的场景。1GTBnr2KWjD02HAL89XX8V8KAx8IS08Lv7koMGQAUwk=
实际开发中,以上几种清理策略可以结合使用。比如 Redis 的内存管理机制结合了定期清理和惰性清理策略。 定期清理通过后台定期扫描一部分键,随机检查并删除已过期的键,从而主动释放内存,减少过期键的堆积。惰性清理则是在访问某个键时,检查其是否已过期,如果已过期则立即删除。这两种策略互为补充:定期清理降低了过期键的占用积累,而惰性清理确保了访问时键的准确性和及时清理,从而在性能和内存使用之间取得平衡。
实现方案
对于我们的项目,由于不像 Redis 一样对空间的限制那么严格,更多的是为了节约成本,所以不需要惰性清理策略,按需运用 “立即清理 + 手动清理 + 定期清理” 即可。
后端开发
1)CosManager 补充删除对象的方法:
/**
* 删除对象
*
* @param key 文件 key
*/
public void deleteObject(String key) throws CosClientException {
cosClient.deleteObject(cosClientConfig.getBucket(), key);
}2)在 PictureService 中开发图片清理方法。
注意,删除图片时,需要先判断该图片地址是否还存在于其他记录里,确认没有才能删除。比如秒传的场景,就有可能多个图片地址指向同一个文件。
此外,还要注意删除对象存储中的文件时传入的是 key(不包含域名的相对路径),而数据库中取到的图片地址是包含域名的,所以删除前要移除域名,从而得到 key。这段鱼皮的视频教程中没有讲,大家可以自行实现。
@Async
@Override
public void clearPictureFile(Picture oldPicture) {
// 判断该图片是否被多条记录使用
String pictureUrl = oldPicture.getUrl();
long count = this.lambdaQuery()
.eq(Picture::getUrl, pictureUrl)
.count();
// 有不止一条记录用到了该图片,不清理
if (count > 1) {
return;
}
// FIXME 注意,这里的 url 包含了域名,实际上只要传 key 值(存储路径)就够了
cosManager.deleteObject(oldPicture.getUrl());
// 清理缩略图
String thumbnailUrl = oldPicture.getThumbnailUrl();
if (StrUtil.isNotBlank(thumbnailUrl)) {
cosManager.deleteObject(thumbnailUrl);
}
}上述代码中,使用了 Spring 的 @Async 注解,可以使得方法被异步调用,记得要在启动类上添加 @EnableAsync 注解才会生效。
@SpringBootApplication
@EnableAsync
@MapperScan("com.yupi.yupicturebackend.mapper")
@EnableAspectJAutoProxy(exposeProxy = true)
public class YuPictureBackendApplication {
public static void main(String[] args) {
SpringApplication.run(YuPictureBackendApplication.class, args);
}
}然后你可以将 clearPictureFile 方法运用到图片删除接口等场景。这里鱼皮给大家抛砖引玉,更多的清理策略大家可以自行实现。
扩展
1)补充更多清理时机:在重新上传图片时,虽然那条图片记录不会删除,但其实之前的图片文件已经作废了,也可以触发清理逻辑。aBxepiWUEGZV9/dC1YWVpHGLHtNF4Mzxu+qzsN+DnFU=
2)实现更多清理策略:比如用 Spring Scheduler 定时任务实现定时清理、编写一个接口供管理员手动清理,作为一种兜底策略。
3)优化清理文件的代码,比如要删除多个文件时,使用 对象存储的批量删除接口 代替 for 循环调用。
4)为了清理原图,可以在数据库中保存原图的地址。
五、其他
比如之前我们每次重启服务器都要重新登陆,既然已经整合了 Redis,不妨使用 Redis 管理 Session,更好地维护登录态。
Redis 分布式 Session
操作方式也很简单,1 分钟就能完成。
1)先在 Maven 中引入 spring-session-data-redis 库:
<!-- Spring Session + Redis -->
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>2)修改 application.yml 配置文件,更改 Session 的存储方式和过期时间:
spring:
# session 配置
session:
store-type: redis
# session 30 天过期
timeout: 2592000
server:
port: 8123
servlet:
context-path: /api
# cookie 30 天过期
session:
cookie:
max-age: 2592000这就搞定了,可以测试下重启服务器后是否还需要重新登陆,并且查看 Redis 中是否有登录相关的 key。