伙伴匹配介绍
介绍:帮助大家找到志同道合的伙伴(h5 项目)
1 需求分析
- 用户去添加标签,标签的分类(要有哪些标签、怎么把标签进行分类)学习方向 java/c++,工作/大学
- 主动搜索:允许用户根据标签去搜索其他用户
- Redis 缓存技术 + 本地
- 组队(允许超过人数、替补)
- 创建房间
- 加入队伍
- 根据标签查询队伍
- 邀请其他人
- 允许用户去修改标签
- 推荐
- 相似度计算 + 本地分布式
2 技术选型
2.1 前端
- Vue 3 开发框架(提高页面开发的效率)
- Vant UI (基于 Vue 的移动端组件库)(React 版本 Zent)
- Vite(打包工具,非常快)
- Nginx
2.2 后端
- Java 编程语言+SpringBoot 框架
- SpringMVC+MyBatis+MyBatisPlus
- Swagger+Knife4i 接口文档
2.3 数据库
- Mysql 数据库
- Redis 缓存
3 项目开发(数据库设计)
标签的分类(要有哪些标签、怎么把标签进行分类)
3.1 设计标签表(分类表)
建议用标签,不要用分类、更灵活
| 性别 | 男、女 |
|---|---|
| 方向 | Java、C++、Go、前端 |
| 正在学 | Spring |
| 目标 | 考研、春招、秋招、社招、考公、竞赛(蓝桥杯)、转行、跳槽 |
| 段位 | 初级、中级、高级、王者 |
| 身份 | 大一、大二、大三、大四、学生、待业、已就业、研一、研二、研三 |
| 状态 | 乐观、有点丧、一般、单身、已婚、有对象 |
用户自己定义标签
3.1.1 字段
| 字段名 | 类型 | 备注 |
|---|---|---|
| id | int | 主键 |
| 标签名 | varchar | 标签名 非空(必须唯一,唯一索引) |
| userld | int | 上传标签的用户(如果要根据 userId 查已上传标签的话,最好加上,普通索引) |
| parentId | int | 父标签 id |
| isParent | tinyint(0,1) | 是否为父标签(分类)0-不是父标签 1- 是父标签 |
| createTime | datatime | 创建时间 |
| updateTime | datatime | 更新时间 |
| isDelete | tinyint(0,1) | 是否删除 |
怎么查询所有标签,并且把标签分好组?按父标签 id 分组,能实现 √
根据父标签查询子标签?根据 id 查询,能实现 √
3.2 修改用户表
用户有哪些标签?
根据自己的实际需求来!!!此处选择第一种
- 直接在用户表补充 tags 字段,['Java',男] 存 json 字符串
- 优点:查询方便、不用新建关联表,标签是用户的固有属性(除了该系统、其他系统可能要用到,标签是用户 的固有属性)节省开发成本
- 查询用户列表,查关系表拿到这 100 个用户有的所有标签 id,再根据标签 id 去查标签表。
- 哪怕性能低,可以用缓存。
- 缺点:用户表多一列,会有点
- 加一个关联表,记录用户和标签的关系
- 关联表的应用场景:查询灵活,可以正查反查
- 缺点:要多建一个表、多维护一个表
- 重点:企业大项目开发中尽量减少关联查询,很影响扩展性,而且会影响查询性能
3.3 队伍表team
3.3.1 字段
| 字段名 | 类型 | 备注 |
|---|---|---|
| id | bigint | 主键(最简单、连续,放url上比较简短,但缺点是爬爬虫) |
| name | 队伍名称 | |
| description | 描述 | |
| maxNum | 最大人数 | |
| expireTime | 过期时间 | |
| userId | 用户Id | |
| createTime | 创建时间 | |
| updateTime | 更新时间 | |
| isDelete | 是否删除 | |
| status | 0-公开,1-私有,2-加密 | |
| password | 密码 |
3.3.2 方式:
建立用户-队伍关系表teamlduserld(便于修改,查询性能高一点,可以选择这个,不用全表遍历)=>选择
用户表补充已加入的队伍字段,队伍表补充已加入的用户字段(不用写多对多的代码,可以直接根据队伍查用户、根据用户查队伍)
3.4 用户-队伍表
| 字段名 | 类型 | 备注 |
|---|---|---|
| id | 主键 | |
| userId | 用户id | |
| teamId | 队伍id | |
| joinTime | 加入时间 | |
| createTime | 创建时间 | |
| updateTime | 更新时间 | |
| isDelete | 是否删除 | |
4 项目开发(前端)
4. 1 项目初始化
4.1.1 用脚手架初始项目
yarn create vite 输入项目名称 yupao-frontend 选着 vue 框架和 ts 语言风格
4.1.2 添加组件库
# yarn (如果安装失败 用npm yarn 可能权限不足)
yarn add vite-plugin-style-import@1.4.1 -D
# 或者 npm
npm i vite-plugin-style-import@1.4.1 -D4.1.3 安装 vant
npm i vant
4.1.3.1 引入组件-按需引入组件样式
npm install -D unplugin-vue-components @vant/auto-import-resolver
4.1.3.2 测试配置
// vite.config.ts
import vue from '@vitejs/plugin-vue';
import AutoImport from 'unplugin-auto-import/vite';
import Components from 'unplugin-vue-components/vite';
import { VantResolver } from '@vant/auto-import-resolver';
export default {
plugins: [
vue(),
AutoImport({
resolvers: [VantResolver()],
}),
Components({
resolvers: [VantResolver()],
}),
],
};
//main.ts
import {createApp} from 'vue'
import App from './App.vue'
// 1. 引入你需要的组件
import { Button } from 'vant';
// 2. 引入组件样式
import 'vant/lib/index.css';
const app = createApp(App);
app.use(Button);
app.mount('#app')
//App.vue
<template>
<HelloWorld msg="Hello Vue 3 + TypeScript + Vite" />
<van-button type="primary">主要按钮</van-button>
<van-button type="success">成功按钮</van-button>
<van-button type="default">默认按钮</van-button>
<van-button type="danger">危险按钮</van-button>
<van-button type="warning">警告按钮</van-button>
</template>4.2 前端主页 + 组件概览
4.2.1 设计
导航条:展示当前页面名称
主页搜索框 => 搜索页 => 搜索结果页面(标签筛选页)
内容
tab 栏:
- 主页(推荐页+广告)
- 搜索框
- banner
- 推荐信息流
- 队伍页
- 用户页(消息 - 暂时考虑发邮件 )
4.2.2 开发
很多页面要复用组件/样式,重复写很麻烦、不利于维护,所以抽象一个通用的布局
4.3 前端页面开发
4.3.1 路由整合
有些组件库可能自带了和 Vue-Router 的整合,所以尽量先看文档。
<!--内容-->
<div id="content">
<router-view></router-view>
</div>
<!--底部tabbar-->
<van-tabbar route @change="onChange">
<van-tabbar-item to="/" icon="home-o" name="index">主页</van-tabbar-item>
<van-tabbar-item to="/team" icon="search" name="team">队伍</van-tabbar-item>
<van-tabbar-item to="/user" icon="friends-o" name="user">个人</van-tabbar-item>
</van-tabbar>4.4 用户登录
router.replace('/'); // todo 跳转到首页 替换历史记录 不是压入 点击返回 不会再回到登录页4.5 主页开发
5 项目开发(后端)
5.1 项目初始化
idea 初始化
5.2 接口开发(搜索标签)
5.2.1 SQL 查询(现简单,可以通过拆分查询进一步优化)
- 允许用户传入多个标签,多个标签都存在才搜索出来 and。like‘%Java%' and like '%C++%'
- 允许用户传入多个标签,有任何一个标签存在就能搜索出来 or。like '%Java%' or like '%C++%'
5.2.2 内存查询(灵活, 可以通过并发进一步优化)
- 如果参数可以分析,根据用户的参数去选择查询方式,比如标签数
- 如果参数不可分析,并且数据库连接足够、内存空间足够,可以并发同时查询,谁先返回用谁。
- 还可以 SQL 查询与内存计算 相结合,比如先用 SQL 过滤掉部分 tag
建议通过实际测试来分析哪种查询比较快,数据量大的时候验证效果更明显!
5.3 后端整合 Swagger+Knife4j 接口文档
5.3.1 什么是接口文档?
写接口信息的文档,每条接口包括:
- 请求参数
- 响应参数
- 错误码
- 接口地址
- 接口名称
- 请求类型
- 请求格式
- 备注
5.3.2 who 谁用?
一般是后端或者负责人来提供,后端和前端都要使用
5.3.3 为什么需要接口文档?
- 有个书面内容(背书或者归档),便于大家参考和查阅,便于沉淀和维护,拒绝口口相传
- 接口文档便于前端和后端开发对接,前后端联调的 介质。后端 => 接口文档 <= 前端
- 好的接口文档支持在线调试、在线测试,可以作为工具提高我们的开发测试效率
5.3.4 怎么做接口文档?
- 手写(比如腾讯文档、Markdown 笔记)
- 自动化接口文档生成:自动根据项目代码生成完整的文档或在线调试的网页。Swagger, Postman(侧重接口管理),apifox, apipost, eolink
5.3.5 接口文档有哪些技巧?
5.3.5.1 Swagger 原理
- 引入依赖 Swagger 或 Knife4j
- 自定义 Swagger 配置类
- 定义需要生成接口文档的代码位置(Controller)
- 干万注意:线上环境不要把接口暴露出去!!!可以通过在SwaggerConfig配置文件开头加上@Profile({"dev","test"})限定配置仅在部分环境开启
- 启动即可
- 可以通过在 controller 方法上添加@Api @ApilmplicitParam()@ApiOperation()等注解来自定义信息
注意
如果 springboot version >= 2.6,需要添加如下配置
spring:
mvc:
pathmatch:
matching-strategy: ant_path_matcherpackage com.lihui.yupao_backend.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Profile;
import springfox.documentation.builders.ApiInfoBuilder;
import springfox.documentation.builders.PathSelectors;
import springfox.documentation.builders.RequestHandlerSelectors;
import springfox.documentation.service.ApiInfo;
import springfox.documentation.service.Contact;
import springfox.documentation.spi.DocumentationType;
import springfox.documentation.spring.web.plugins.Docket;
import springfox.documentation.swagger2.annotations.EnableSwagger2WebMvc;
/**
* 自定义 Swagger 接口文档的配置
*/
@Configuration
@EnableSwagger2WebMvc
@Profile("prod")
public class SwaggerConfig {
@Bean(value = "defaultApi2")
public Docket defaultApi2() {
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo())
.select()
// 这里一定要标注你控制器的位置
.apis(RequestHandlerSelectors.basePackage("com.lihui.yupao_backend.controller"))
.paths(PathSelectors.any())
.build();
}
/**
* api 信息
*
* @return
*/
private ApiInfo apiInfo() {
return new ApiInfoBuilder()
.title("用户中心")
.description("用户中心接口文档")
.termsOfServiceUrl("https://github.com/lihuibear")
.contact(new Contact("lihuibear", "https://github.com/lihuibear", "xxx@qq.com"))
.version("1.0")
.build();
}
}5.3 后端校验修改信息不能为空
// todo
5.4 分页查询
// 插件配置
package com.lihui.yupao_backend.config;
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@MapperScan("com.lihui.yupao_backend.mapper")
public class MybatisPlusConfig {
/**
* 添加分页插件
*/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL)); // 如果配置多个插件, 切记分页最后添加
// 如果有多数据源可以不配具体类型, 否则都建议配上具体的 DbType
return interceptor;
}
}
//
@GetMapping("/recommend")
public BaseResponse<Page<User>> recommendUsers(long pageSize, long pageNum, HttpServletRequest request) {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
Page<User> userList = userService.page(new Page<>(pageNum, pageSize), queryWrapper);
return ResultUtils.success(userList);
}数据库慢? => 数据过多 =>从磁盘读取,数据越多越慢
预先把数据查出来,放到一个更快读取的地方,不用再查数据库了。(缓存) =>什么时候存到缓存?
预加载缓存,定时更新缓存。(定时任务)
多个机器都要执行任务么?(分布式锁:控制同一时间只有一台机器去执行定时任务,其他机器不用重复执行了)
5.5 组队功能
5.5.1 分析
用户可以创建一个队伍,设置队伍的人数、队伍名称(标题)、描述、超时时间
队长、剩余人数
聊天?
公开或private或加密
信息流中不展示已过期的队伍
根据标签或名称搜索队伍
用户创建队伍最多5个
修改队伍信息
用户可以加入未满的队伍(其他人、未满、未过期)
是否需要队长同意,筛选审批?
用户可以退出队伍(如果是队长,权限转移给第二早加入的用户)允许加入多个队伍,但是要有个上限
队长可以解散队伍
分享队伍=>邀请其他用户加入队伍
5.5.2 实现
5.5.2.1 库表设计
见数据库部分
5.5.2.2 系统接口设计
5.5.2.2.1 创建队伍
- 请求参数是否为空?
- 是否登录,未登录不允许创建
- 校验信息
- 队伍人数>1且<=20
- 队伍标题<=20
- 描述<=512
- status是否公开(int)不传默认为0(公开)
- 如果status是加密状态,一定要有密码,且密码<=32
- 超时时间>当前时间
- 校验队伍最多创建5个
- 插入队伍信息到队伍表
- 插入用户=>队伍关系到关系表
5.5.2.2.2 查询队伍列表
分页展示队伍列表,根据名称、最大人数等搜索队伍,信息流中不展示已过期的队伍
从请求参数中取出队伍名称等查询条件,如果存在则作为查询条件
从请求参数中取出队伍名称,如果存在则作为查询条件
不展示已过期的队伍(根据过期时间筛选)
只有管理员才能查看加密还有非公开的房间
关联查询已加入队伍的用户信息
关联查询已加入队伍的用户信息(可能会很耗费性能建议大家用自己写SQL的方式实现) //todo
实现方式
自己写sql
java// 1. 自己写 SQL // 查询队伍和创建人的信息 // select * from team t left join user u on t.userId = u.id // 查询队伍和已加入队伍成员的信息 // select * // from team t // left join user_team ut on t.id = ut.teamId // left join user u on ut.userId = u.id;
5.5.2.2.3 修改队伍信息
修改队伍信息
- 判断请求参数是否为空
- 查询队伍是否存在
- 只有管理员或者队伍的创建者可以修改
- 如果用户传入的新值和老值一致,就不用update了(可自行实现,降低数据库使用次数)
- 如果队伍状态改为加密,必须要有密码
- 更新成功
5.5.2.2.3 用户加入队伍
其他人、未满未过期,允许加入多个队伍,但是要有个上限
- 用户最多加入5个队伍
- 队伍必须存在,只能加入未满、未过期其他人创建的队伍
- 如果加入的队伍是加密的,必须匹配密码才可以
- 禁止加入私有的队伍
- 不能重复加入已经加入的队伍(幂等性)
- 新增队伍-用户关联信息
并发请求是可能出现问题
5.5.2.2.4 退出队伍
如果队长退出,权限转移给第二早加入的用户一一先来后到
- 校验请求参数(请求参数 队伍id)
- 如果队伍
- 队伍只剩下一人,队伍解散
- 校验队伍是否存在
- 校验是否已近加入
- 还有其他人
- 队长退出,权限转移
- 其他人退出,直接退出
5.6 随机匹配
6 项目开发(部署上线)
7 补补知识
7.1 开发页面经验
- 多参考
- 从整体到局部
- 先想清楚页面要做成什么样子,再写代码
7.2 SQL 语言分类
- DDL define 建表、操作表
- DML manage 更新删除数据,影响实际表里的内容
- DCL control 控制,权限
- DQL query 查询 select
7.3 解析 ISON 字符串
序列化:java 对象转成 json
反序列化:把 json 转为 java 对象
java json 序列化库
- gson (Google 出品)
- fastjson(阿里出品,快,但是有漏洞)
- jackson
- kryo
7.4 java8 特性
- stream / parallelStream 流失处理
- Optional 可选类
7.5 后端整合 Swagger+Knife4j 接口文档
7.5.1 什么是接口文档?
写接口信息的文档,每条接口包括:
- 请求参数
- 响应参数
- 错误码
- 接口地址
- 接口名称
- 请求类型
- 请求格式
- 备注
7.5.2 who 谁用?
一般是后端或者负责人来提供,后端和前端都要使用
7.5.3 为什么需要接口文档?
- 有个书面内容(背书或者归档),便于大家参考和查阅,便于沉淀和维护,拒绝口口相传
- 接口文档便于前端和后端开发对接,前后端联调的 介质。后端 => 接口文档 <= 前端
- 好的接口文档支持在线调试、在线测试,可以作为工具提高我们的开发测试效率
7.5.4 怎么做接口文档?
- 手写(比如腾讯文档、Markdown 笔记)
- 自动化接口文档生成:自动根据项目代码生成完整的文档或在线调试的网页。Swagger, Postman(侧重接口管理),apifox, apipost, eolink
7.5.5 接口文档有哪些技巧?
7.5.5.1 Swagger 原理
- 引入依赖 Swagger 或 Knife4j
- 自定义 Swagger 配置类
- 定义需要生成接口文档的代码位置(Controller)
- 干万注意:线上环境不要把接口暴露出去!!!可以通过在SwaggerConfig配置文件开头加上@Profile({"dev","test"})限定配置仅在部分环境开启
- 启动即可
- 可以通过在 controller 方法上添加@Api @ApilmplicitParam()@ApiOperation()等注解来自定义信息
注意
如果 springboot version >= 2.6,需要添加如下配置
spring:
mvc:
pathmatch:
matching-strategy: ant_path_matcherpackage com.lihui.yupao_backend.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Profile;
import springfox.documentation.builders.ApiInfoBuilder;
import springfox.documentation.builders.PathSelectors;
import springfox.documentation.builders.RequestHandlerSelectors;
import springfox.documentation.service.ApiInfo;
import springfox.documentation.service.Contact;
import springfox.documentation.spi.DocumentationType;
import springfox.documentation.spring.web.plugins.Docket;
import springfox.documentation.swagger2.annotations.EnableSwagger2WebMvc;
/**
* 自定义 Swagger 接口文档的配置
*/
@Configuration
@EnableSwagger2WebMvc
@Profile("prod")
public class SwaggerConfig {
@Bean(value = "defaultApi2")
public Docket defaultApi2() {
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo())
.select()
// 这里一定要标注你控制器的位置
.apis(RequestHandlerSelectors.basePackage("com.lihui.yupao_backend.controller"))
.paths(PathSelectors.any())
.build();
}
/**
* api 信息
*
* @return
*/
private ApiInfo apiInfo() {
return new ApiInfoBuilder()
.title("用户中心")
.description("用户中心接口文档")
.termsOfServiceUrl("https://github.com/lihuibear")
.contact(new Contact("lihuibear", "https://github.com/lihuibear", "xxx@qq.com"))
.version("1.0")
.build();
}
}7.6 看上了网页信息,怎么抓到?
7.6.1 分析原网站是怎么获取这些数据的?哪个接口?
按 F 12 打开控制台,查看网络请求,复制 curl 代码便于查看和执行:
curl "https://api.zsxq.com/v2/hashtags/48844541281228/topics?count=20" ^
-H "authority: api.zsxq.com" ^
-H "accept: application/json, text/plain, */*" ^
-H "accept-language: zh-CN,zh;q=0.9" ^
-H "cache-control: no-cache" ^
-H "origin: https://wx.zsxq.com" ^
-H "pragma: no-cache" ^
-H "referer: https://wx.zsxq.com/" ^
--compressed- 用程序去调用接口 (java okhttp httpclient / python 都可以)
- 处理(清洗)一下数据,之后就可以写到数据库里
7.6.2 流程
- 从 excel 中导入全量用户数据,判重 。 easy excel:https://alibaba-easyexcel.github.io/index.html
- 抓取写了自我介绍的同学信息,提取出用户昵称、用户唯一 id、自我介绍信息
- 从自我介绍中提取信息,然后写入到数据库中
7.6.3 EasyExcel
7.6.3.1 两种读对象的方式
- 确定表头:建立对象,和表头形成映射关系
- 不确定表头:每一行数据映射为 Map <String, Object>
7.6.3.2 两种读取模式
- 监听器:先创建监听器、在读取文件时绑定监听器。单独抽离处理逻辑,代码清晰易于维护;一条一条处理,适用于数据量大的场景。
- 同步读:无需创建监听器,一次性获取完整数据。方便简单,但是数据量大时会有等待时常,也可能内存溢出。
7.7 前端页面跳转传值
- uery=>urlsearchParams,url后附加参数,传递的值长度有限
- vuex(全局状态管理),搜索页将关键词塞到状态中,搜索结果页从状态取值
7.8 Session 共享
种session的时候注意范围,cookie.domain
比如两个域名:
aaa.lihui.com
bbb.lihui.com
如果要共享cookie,可以种一个更高层的公共域名,比如lihui.com
7.8.1 为什么服务器A登录后,请求发到服务器B,不认识该用户?
7.8.1.1 原因
用户在A登录,所以sessign(用户登录信息)存在了A上
结果请求B时,B没有用户信息,所以不认识

7.8.1.2 解决方案 共享存储
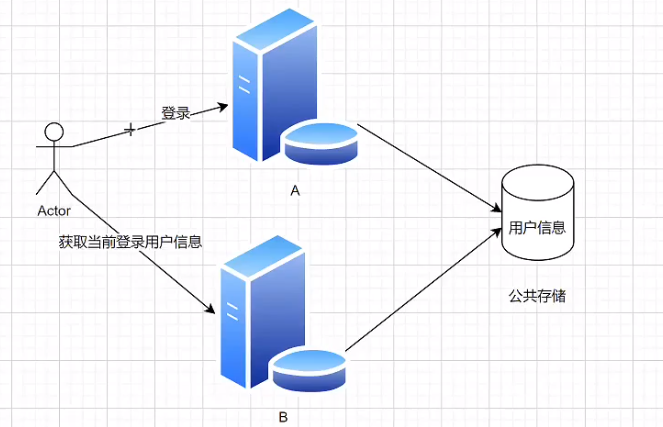
如何共享存储?
- Redis(基于内存的K/V数据库)此处选择Redis,因为用户信息读取/是否登录的判断极其频繁,Redis基于内存,读写性能很高,简单的数据单机 gps5w-10w
- MySQL
- 文件服务器ceph
7.9 Session 共享实现
7.9.1 Redis安装+配置
windows安装 Redis-x64-5.0.14.1.zip
redis管理工具 密码:3mg8 quick redis
7.9.2 spring项目引入redis相关
7.9.2.1 操作redis
<!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-data-redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>2.6.2</version>
</dependency>7.9.2.2 spring-session-redis整合
实际上是spring-session 和redis 整合,使得自动将session存储到redis中
<!-- https://mvnrepository.com/artifact/org.springframework.session/spring-session-data-redis -->
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
<version>2.6.2</version>
</dependency>7.9.3 修改spring-session 存储配置
spring.session.store-type
默认是 none,表示存在单台服务器内存中
store-type: redis 表示从redis读写session
7.10 模拟用户 导入数据
- 可视化界面:适合一次性导入,数据量可控
- 写程序:for循环,建议分批,不要一起导入(可以用接口控制)要保证可控、幂等性、注意测试库和正式库不同
- 执行SQL语句,适合小规模数据
7.10.1 编写一次性任务
7.10.1.1 for 循环 插入数据的问题
未修改 2000+ms
- 建立和释放数据库链接(批量查询解决 修改500+ms)
- for 循环是绝对线性的
并发要注意执行的先后顺序无所谓,不要用到非并发类的集合
private ExecutorService executorService = new ThreadPoolExecutor(40, 1000, 10000, TimeUnit.MINUTES, new ArrayBlockingQueue<>(10000));
//CPU密集型:分配的核心线程数=CPU-1
//IO密集型:分配的核心线程数可以大于CPU核数7.11 缓存和分布式缓存
7.11.1 数据查询慢 怎么办
用缓存:提前把数据取出来保存好(通常保存到读写更快的介质,比如内存),就可以更快地读写。
7.11.1.1 缓存的实现
- Redis(分布式缓存)
- memcached(分布式)
- Etcd(云原生架构的一个分布式存储,适合存储配置,扩容能力强)
- ehcache(单机)
- 本地缓存(Java内存Map)
- Caffeine(Java内存缓存,高性能)
- Google Guava
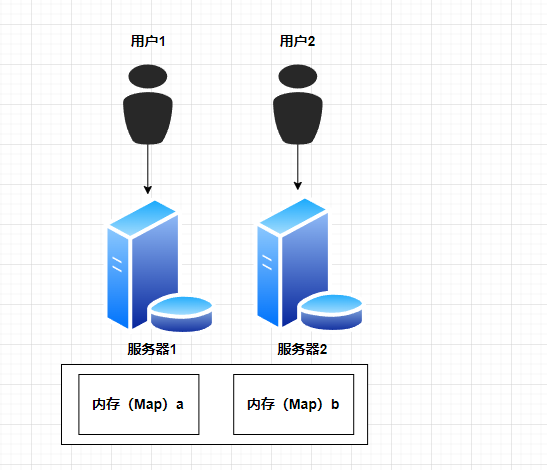
7.11.1.2 为什么需要分布式缓存
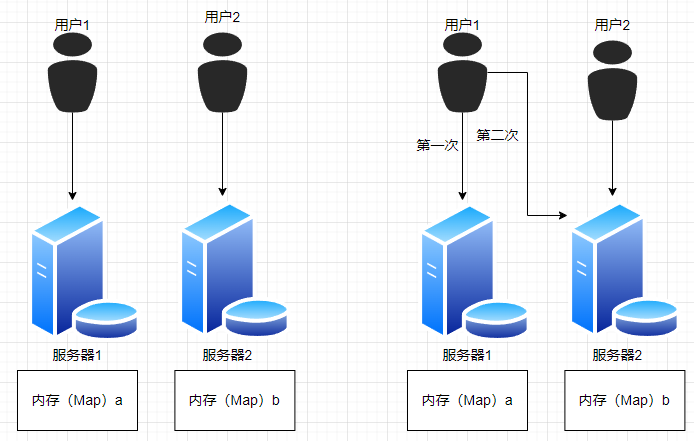
服务需要部署到多台服务器上,但是内存是分开的,造成数据不一致
解决方法
公共存储内存=> Redis
7.12 Redis
NoSQL,key-value存储系统
区别于Mysql(关系型数据库),Redis存储的是键值对
7.12.1 Redis的数据结构
String 字符串类型:name:"lihiu"
List 列表:names:["lihui","lihuihui","lihui"]
Set 集合:names:["lihui","lihuihui"] (值不能重复)
Hash 哈希:nameAge:{ "lihui":1,"lihuihui",2 } (键不能重复)
Zset 集合:names:{lihui-9,lihuihui-2} (加入一个分数,从小到大排序,适合排行榜)
bloomfilter(布隆过滤器,主要从大量的数据中快速过滤值,比如邮件黑名单拦截)
geo (计算地理位置)
hyperloglog(pv/uv)
pub/sub(发布订阅,类似消息队列)
BitMap(001010101010101010101010101)
7.12.2 Java里的实现方式
7.12.2.1 Spring Data Redis(推荐)
通用的数据访问框架,定义了一组增删改查的接口
mysql 、redis、jpa
引入
xml<!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-data-redis --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> <version>2.6.2</version> </dependency>配置
ymlspring: #redis配置 redis: host: localhost port: 6379 database: 0
7.12.2.2 Jedis
独立于 Spring 操作 Redis 的Java客户端
要配合Jedis Pool使用
7.12.2.3 Lettuce
高阶的操作Redis的Java客户端
异步、连接池(可以复用)
7.12.2.4 Redisson
分布式操作Redis的Java客户端,让你像在使用本地的集合一样操作Rediss(分布式Redis数据网格)
7.12.2.5 对比
- 果你用的是Spring,并且没有过多的定制化要求,可以用
Spring Data Redis,最方便 - 如果你用的不是Spring,并且追求简单,并且没有过高的性能要求,可以用Jedis
- 如果你的项目不是Spring,并且追求高性能、高定制化,可以用Lettuce
- 如果你的项目是分布式的,需要用到一些分布式的特性(比如分布式锁、分布式集合),推荐用Redisson
7.12.3 自定义序列化
出现以下原因是因为Redis序列化问题

package com.lihui.yupao_backend.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.RedisSerializer;
/**
* RedisTemplate 配置
*/
@Configuration
public class RedisTemplateConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(connectionFactory);
redisTemplate.setKeySerializer(RedisSerializer.string());
return redisTemplate;
}
}引入一个库时,先写测试类
7.12.4 设计缓存Key
不同用户看到的数据不同
systemld:moduleld:func:options(不要和别人冲突)
yupao:user:recommed:userId
redis内存不能无限增加 记得设置过期时间
7.12.5 缓存预热
问题:第一个用户访问还是很慢
缓存预热也能一定程度上保护数据库
分析优缺点的时候,要打开思路,从整个项目从0到1的链路上去分析
缓存预热优点
- 解决上面的问题,可以让用户始终访问很快
缓存预热缺点
- 增加开发成本(你要额外的开发、设计)
- 预热的时机和时间如果错了,有可能你缓存的数据不对或者太老
- 需要占用额外空间
7.12.5.1 怎么缓存预热
- 定时
- 模拟触发(手动)
定时 =>
用定时任务,每天刷新所有用户的推荐列表
注意点:
- 缓存预热的意义
- 缓存的空间不能无限,要预留其他缓存
- 缓存数据的周期(每XXX)
7.12.6定时任务实现
- Spring Scheduler(springboot默认整合了)
- Quartz(独立于Spring存在的定时任务框架)
- XXL-Job之类的分布式任务调度平台(界面+sdk)
7.12.6.1 Spring Scheduler
- 主类开启
@EnableScheduling - 给要定时执行的方法添加
@Scheduled注解,指定cron表达式或者执行频率
7.12.6.2 控制定时任务的执行
为啥?
- 浪费资源,想象1w台服务器同时“打鸣”
- 脏数据,比如重复插入
要控制定时任务在同一时间只有1个服务器能执行。
怎么做?
- 分离定时任务程序和主程序,只在1个服务器运行定时任务。=>成本太大
- 写死配置,每个服务器都执行定时任务,但是只有ip符合配置的服务器才真实执行业务逻辑,其他的直接返回。=>成本最低,但是我们的IP可能不是固定的,把IP写的太死了
- 动态配置,配置是可以轻松的、很方便地更新的(代码无需重启),但是只有ip符合配置的服务器才真实执行业务逻辑。=>问题:服务器多了、IP不可控还是很麻烦,还是要人工修改
- 数据库
- Redis
- 配置中心(Nacos、Apollo、Spring Cloud Config)
- 分布式锁,只有抢到锁的服务器才能执行业务逻辑。=>坏处:增加成本;好处:不用手动配置,多少个服务器都一样
7.13 锁、分布式锁
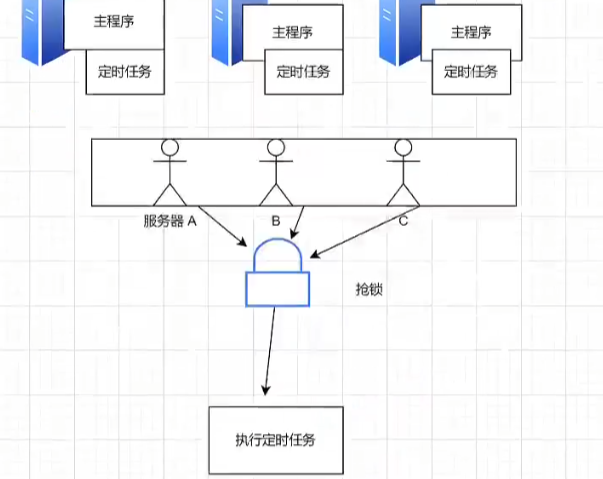
7.13.1 锁
有限资源的情况下,控制同一时间(段)只有某些线程(用户/服务器)能访问到资源。
java实现锁synchronized关键字,但是只对当前(单个)jvm有效
7.13.2 分布式锁
为什么需要分布式锁?
- 有限资源的情况下,控制同一时间(段)只有某些线程(用户/服务器)能访问到资源。
- 单个锁(比如synchronized)只对单个JVM有效
7.13.2.1 分布式锁实现的关键
7.13.2.1.1 抢锁机制
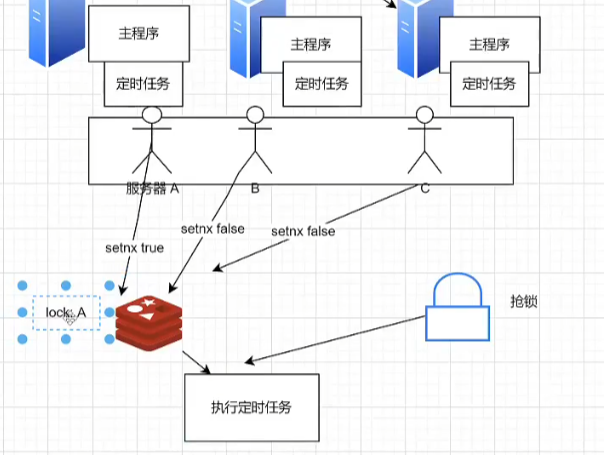
怎么保证同一时间只有1个服务器能抢到锁?
核心思想就是:先来的人先把数据改成自己的标识(服务器ip),后来的人发现标识已存在,就抢锁失败,继续等待。等先来的人执行方法结束,把标识清空,其他的人继续抢锁。
MySQL数据库:select for update 行级锁(最简单)。
乐观锁
✅Redis实现(存标识):内存数据库、读写速度快 ,支持setnx、lua脚本,比较方便我们实现分布式锁。
setnx:set if not exists如果不存在,则设置;只有设置成功才会返回true,否则返回false
注意⚠️:
用完锁要释放(腾地方 )
锁一定要加过期时间
如果方法执行时间过长,锁提前过期了 问题
- 连锁效应:释放掉了别人的锁
- 这样还是会存在多个方法同时执行的情况
解决方案:
续期
javaboolean end = false; new Thread(() ->{ if(!end){ 续期 } }) end =true;
释放锁的时候,有可能先判断出是自己的锁,但这时锁过期了,最后还是释放了别人的锁
java//原子操作 if(get lock == A){ //set lock B =>不允许执行 del lock }Redis+lua脚本实现
Redis如果是集群(而不是只有一个Redis),如果分布式锁的数据不同步怎么办? 红锁:Redisson--红锁(Redlock)--使用/原理-CSDN博客
Zookeeper(不推荐)
7.14 Redisson 实现分布式锁
Java客户端 数据网络
实现了很多Java里支持的接口和数据结构
Redisson是一个java操作Redis的客户端,提供了大量的分布式数据集来简化对Redis的操作和使用,可以让开发者像使用本地集合一 样使用Redis,完全感知不到Redis的存在。
7.14.1 两种引入方式
- springbootstarter引l入(不推荐,版本迭代太快,容易冲突)redisson/redisson-spring-boot-starter at master · redisson/redisson · GitHub
- 直接引入Getting Started - Redisson Reference Guide
7.14.2 示例代码
// list 数据存在本地JVM内存中
List<String> list = new ArrayList<>();
list.add("lihui");
String JVMlist = list.get(0);
System.out.println("list:"+JVMlist);
list.remove(0);
//数据存在redis的内存中
RList<String> rList = redissonClient.getList("test-list");
//rList.add("lihui");
String Redislist = rList.get(0);
System.out.println("rlist:"+Redislist);
rList.remove(0);7.14.3 定时任务+锁
- waitTime 设置为 0 只抢一次,抢不到就放弃
- 注意 释放锁要写在finally里面
7.14.3.1 看门狗机制
redisson中提供的续期机制
开一个监听线程,如果方法还没执行完,就帮你重置redis锁的过期时间
原理:
- 监听当前线程,默认过期时间是30秒,每10秒续期一次(补到30秒)
- 如果线程挂掉(注意debug模式也会被它当成服务器宕机),则不会续期
package com.lihui.yupao_backend.job;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.lihui.yupao_backend.mapper.UserMapper;
import com.lihui.yupao_backend.model.domain.User;
import com.lihui.yupao_backend.service.UserService;
import lombok.extern.slf4j.Slf4j;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.ValueOperations;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.TimeUnit;
@Component
@Slf4j
public class PreCacheJob {
@Resource
private UserMapper userMapper;
@Resource
private UserService userService;
@Resource
private RedisTemplate<String, Object> redisTemplate;
@Resource
private RedissonClient redissonClient;
//重点用户
private List<Long> mainUserList = Arrays.asList(1l);
//每天执行一次,预热推荐用户 缓存
@Scheduled(cron = "0 0 0 * * ?")
public void doCacherecommendUser() {
RLock lock = redissonClient.getLock("yupao:precachejob:docache:lock");
try {
//只有一个线程能获取到锁
if (lock.tryLock(0, 30000, TimeUnit.MILLISECONDS)) {
for (Long UserId : mainUserList) {
// 如果没有缓存,则查询数据库
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
Page<User> userPage = userService.page(new Page<>(1, 20), queryWrapper);
String reidsKey = String.format("yupao:user:recommed:%s", UserId);
ValueOperations<String, Object> valueOperations = redisTemplate.opsForValue();
// 将查询结果存入缓存
try {
valueOperations.set(reidsKey, userPage, 30000, TimeUnit.MILLISECONDS);
} catch (Exception e) {
log.error("redis set error", e);
}
}
}
} catch (InterruptedException e) {
log.error("doCacheJob error", e);
} finally {
//只能释放自己的锁
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
}7.15 为什么需要请求参数包装类?
请求参数名称/类型和实体类不一样
有一些参数用不到,如果要自动生成接口文档,会增加理解成本
多个实体类映射到同一个对象
7.16 为什么需要包装类?
可能有些字段需要隐藏,不能返回给前端或者有些字段某些方法是不关心的
7.17 事物注解
要不数据操作都成功,要不都失败
@Transactional(rollbackFor = Exception.class)8 代码板子
8.1 内存查询与 SQL 查询比较
/**
* 根据标签搜索用户 SQL查询
* <p>
* 根据标签搜索用户 SQL查询
*/
@Override
public List<User> searchUsersByTags(List<String> tagNameList) {
if (CollectionUtils.isEmpty(tagNameList)) {
throw new BusinessException(ErrorCode.PARAMS_ERROR);
}
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
for (String tagName : tagNameList) {
queryWrapper = queryWrapper.like("tags", tagName);
}
List<User> userList = userMapper.selectList(queryWrapper);
return userList.stream().map(this::getSafetyUser).collect(Collectors.toList());
}
/**
* 根据标签搜索用户 内存查询
*/
@Override
public List<User> searchUsersByTags(List<String> tagNameList) {
if (CollectionUtils.isEmpty(tagNameList)) {
throw new BusinessException(ErrorCode.PARAMS_ERROR);
}
//1.先查询所有的用户
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
List<User> userList = userMapper.selectList(queryWrapper);
Gson gson = new Gson();
//2.遍历用户列表,查询标签列表 内存中判断是否包含要求的标签
return userList.stream().filter(user -> {
String tagsStr = user.getTags();
if (StringUtils.isBlank(tagsStr)) {
return false;
}
Set<String> temptagNameList = gson.fromJson(tagsStr, new TypeToken<Set<String>>() {
}.getType());
for (String tagName : tagNameList) {
if (!temptagNameList.contains(tagName)) {
return false;
}
}
return true;
}).map(this::getSafetyUser).collect(Collectors.toList());
}
// 测试
@Test
public void testsearchUsersByTags() {
List<String> tags = Arrays.asList("java");
List<User> userList = userService.searchUsersByTags(tags);
Assertions.assertNotNull(userList);
}9 错误记录
9.1 前端没有发送到后端数据
tags 写成了 tsgs
10 知识记录
- redis
- 定时任务
- 缓存雪崩
- 锁
- 分布式锁
- 微服务
- 红锁
缓存穿透 恶意访问不存在的数据 比如id<0的,逻辑判断会降低这种分析