SQL知识点
CREATE
基本表
定义基本表 CREATE TABLE
CREATE TABLE 表名(
列名1 数据类型 列级完整性约束条件,# 如果没有完整性约束条件,可以不写
列名n 数据类型 列级完整性约束条件,
表级完整性约束条件1,
表级完整性约束条件n,
);数据类型
| 数据类型 | 说明 |
|---|---|
| CHAR(n) | 长度为 n的字符型 |
| VARCHAR(n) | 最大长度为n的变长字符型 |
| NUMBER(n) | 长度为 n的数字型 |
| INT | 长整型(4B) |
| SMALLINT | 短整型(2B) |
| BIGINT | 大整型 (8B) |
| FLOAT(n) | 精度至少为n位数字的浮点数 |
| DATE | 日期,格式为YYYY-MM-DD |
| TIME | 时间,格式为HH:MM:SS |
列级完整性约束条件
| 列级完整性约束条件 | 说明 |
|---|---|
| PRIMARY KEY | 主码:当只有一个主码时,可直接在对应的属性列标注 |
| NOT NUL | 非空:表示该属性列不能取空值 |
| UNIQUE | 唯一值:表示该属性列只能取唯一值 |
| CHECK( ) | 检查:检查该列是否满足某个条件,如CHECK(某属性>20) |
技巧
只需要判断是否非空、唯一值、检查即可,主码我们可以在表级完整性约束条件设置,这样会避免多个属性构成主码(联合主码)的错误
表级完整性约束条件
| 表级完整性约束条件 | 说明 |
|---|---|
| PRIMARY KEY(列名 1,列名 n) | 实体完整性:当主码由多个属性构成时,必须作为表级完整性进行定义 |
| FOREIGNKEY(列名1)REFERENCES被参照表(列名1) | 参照完整性 |
eg
CREATE TABLE TAB1
( Sno VARCHAR(10),
Cno NUMBER(10),
Grade INT NOT NULL,
PRIMARY KEY(Sno, Cno),
FOREIGN KEY(Sno) REFERENCES TAB2(Sno)
);SELECT
一般格式
SELECT DISTINCT/ALL 目标列表达式 # 要显示的属性列
FROM 表名/视图名 #查询的对象
WHERE 条件表达式 #查询条件
GROUPBY列名名HAVING条件表达式 #查询结果分组
ORDERBY列名次序;#最终查询结果排序基本查询
SELECT 目标列表达式
查询指定列
SELECT 列名1,列名2,…,列名n
eg:
SELECT X,Y
FROM TAB1;查询全部列
SELECT *
eg:
SELECT *
FROM TAB1;查询计算后的值
SELECT 表达式 以是算术表达式、字符串常量、函数等等
eg:查询TAB表(假定有一项属性age记录人们的年龄)中人们的出生日期
SELECT 2022-age
FROM TAB;改变查询结果的列标题
SELECT 列名 别名
eg:查询TAB表中的×和Y属性列,并在结果中用别名x1和y1显示
SELECT X x1, Y y1
FROM TAB;取消查询结果中的重复行
SELECT DISTINCT 列名
eg:查询TAB表中的×属性,并去掉结果中的重复列
SELECT DISTINCT X, # 如果没有用DISTINCT,则默认为ALL
FROM TAB;聚集函数
注意:当聚集函数遇到空值时,都跳过空值,只处理非空值
聚集函数只能用于SELECT语句和GROUP BY中的HAVING子句(见后部分)

WHERE 条件表达式
比较大小
常用比较运算符: = | > < >= !< <> !> !<
eg:查询 SC 表中全体计算机学生的姓名
SELECT Sname
FROM SC
WHERE Sdept='cs';eg:查询TAB 表中X>20的Y
SELECT Y
FROM TAB
WHERE X>20;确定范围
WHERE 列名 BETWEEN 最小值 AND 最大值;
eg:查询 TAB表上 age 在 20到 30 之间的人的 name 和 sex
SELECT name, sex
FROM TAB
WHERE age BETWEEN 20 AND 30;WHERE 列名 NOT BETWEEN 最小值 AND 最大值;
eg:查询 TAB 表上 age 不在 20 到 30 之间的人的 name 和 sex
SELECT name,sex
FROM TAB
WHERE age NOT BETWEEN 20 AND 30;确定集合
WHERE 列名 IN(列名 1,'列名 n); eg:在SC表的 Sdept 列中查找属于计算机专业(CS)、数学专业(MA)、信息专业(IS)的学生姓名(S_name)
SELECT S_name
FROM SC
WHERE Sdept IN (CS", 'MA, "IS'");字符匹配
通配符:写在字符串当中,用来求一些有特殊条件的字符串
%表示任意长度(可以为0)的字符串。如a%b,表示以a开头,b结尾的任意长度字符串
_表示单个字符。如a_b,表示以a开头b 结尾的长度为3的字符串
注意:在ASCII码表中,一个汉字的长度为2
转义字符:字符串中紧跟在转义字符后的字符'%或_不再具有通配符的含义
设置转义字符的语句为ESCAPE‘符号',该符号可以自己设置,一般采用\‘
例如需要查找的字符串为'50%',那么应写"50%,否则会查找以50开头的不定长字符串
WHERE 列名 LIKE '字符串' ESCAPE '\';
eg.在 Student 表中查找所有姓刘且全名为 3 个汉字的学生的 Sname、Sno和 Ssex
SELECT Sname, Sno, Ssex
FROM Student
WHERE Sname LIKE'刘____eg.在SC表中查找课程名(Cname)为 DB_Design 的课程号(Cno)
SELECT Cno
FROM SC
WHERE Cname LIKE 'DB\_Design' ESCAPE '\';WHERE 列名 NOT LIKE ‘字符串' ESCAPE '\'; eg.在Student表中查找所有不姓刘的学生的Sname
SELECT Sname
FROM Student
WHERE Sname NOT LIKE '刘%";空值查询
WHERE 列名 IS NULL;
eg.在SC表中查询缺少成绩(Grade)的学生的姓名(Sname)
SELECT Sname
FROM SC
WHERE Grade IS NULL;WHERE 列名 IS NOT NULL;
eg.查询全部有成绩(Grade)的学生的姓名(Sname)
SELECT Sname
FROM SC
WHERE Grade IS NOT NULL;多重条件查询
WHERE 条件表达式 AND 条件表达式; WHERE 条件表达式 OR 条件表达式;
可以用AND或者OR将上述各类条件表达式组合在一起。其中,AND的优先级大于OR
GROUP BY 列名 HAVING 条件表达式
用于将查询结果按某一列或多列的值分组,值相等的为一组
目的是细化聚集函数的作用对象,分组后聚集函数将作用于每一个组,每一组都有一个函数值
GROUPBY 列名
eg.求SC表中,各个课程号(Cno)下相应的选课人数(Sno)
SELECT Cno, COUNT(Sno)
FROM SC
GROUP BY Cno;#表示具有相同Cno值的元组为一组,对每一组用COUNT进行计算,求得该组的人数GROUP BY 列名HAVING 筛选条件
与WHERE的区别:
HAVING用于从组中选择满足条件的组
WHERE用于从基本表或视图中选择满足条件的元组(注意:WHERE子句不可以接聚集函数)
eg.在SC表中查询平均成绩(Grade)大于等于90的学生学号(Sno)和平均成绩(Grade)
SELECT Sno,Grade
FROM SC
GROUP BY Sno
HAVING AVG(Grade)>=90;ORDER BY 次序
ORDER BY 列名1 列名n ASC
对查询结果按照一个或多个属性列的升序排列(若不表明次序,默认为升序)
ORDER BY 列名1 列名 n DESC
对查询结果按照一个或多个属性列的降序排列
eg.查序SC表中Cno为3的学生的Sno和Grade,结果按照Grade的降序排列
SELECT Sno, Grade
FROM SC
WHERE Cno='3'
ORDER BY Grade DESC;连接查询
两表连接查询
WHERE 表名1.列名1 比较运算符 表名2.列名2:当列名在参与连接的各表中唯一时,可省去表名前缀
eg.查询Student表中学生的情况以及SC表中他们对应的选课情况,要求在一个查询结果中展示
SELECT Student.*,SC.* #若两个表中有相同名的属性列,自然连接
FROM Student, SC
WHERE Student.Sno=SC.Sno; #用Sno作为连接字段,将两个表连接在一起若想获得自然连接,则列举全部属性列,并去掉一个相同的属性列即可。可以将上述SELECT语句改写如下
SELECT Student.Sno,Sname,Ssex,Sage,Sdept, Cno,Grade
eg.在Student表和SC表中,查询选修了2号课程(Cno='2")且成绩(Grade)在90分以上的学生学号(Sno)和姓名(Sname)
SELECT Student.Sno,Sname
FROM Student,SC
WHERE Student.Sno=SC.Sno AND SC.Cno='2' AND SC.Grade>90; #AND用作多重条件单表连接查询
eg.在Course表中查询先修课的先修课(即间接先修课),其中课程号为Cno,先修课程号为Cpno
SELECT FIRST.Cno,SECOND.Cpno #利用下述别名进行选择
FROM Course FIRST,Course SECOND #为这个表取两个别名
WHER EFIRST.Cpno=SECOND.Cno;外连接查询
将悬浮元组保留在结果关系中,没有属性值的位置填上NULL
左外连接查询
FROM 表名1 LEFT OUTER JOIN 表名2 ON(连接条件); 也可以将ON换成USING,去掉结果中的重复值
右外连接查询
FROM 表名1 RIGHT OUTER JOIN 表名2 ON(连接条件); eg.以Student表为主体列,排出每个学生的基本情况和选课情况(SC表中),没选课的学生依旧保留在结果中
SELECT Student.Sno,Sname,Ssex,Sage,Sdept,Cno,Grade
FROM Student
LEFT OUTER JOIN SC ON(Student.Sno=SC.Sno);#左外连接多表连接查询
WHERE 表名1.列名1=表名2.列名2 AND 表名2.列名2=表名3.列名3;
多表连接一般是先进行两个表的连接操作,再将其连接结果与第三个表执行连接
eg.从Student表、SC表、Course表中查询每个学生的学号(Sno)、姓名(Sname)、课程(Cname)和成绩(Grade)
SELECT Student.Sno,Sname,Cname,Grade
FROM Student,SC,Course
WHERE Student.Sno=SC.Sno AND SC.Cno=Course.Cno;嵌套查询



集合查询
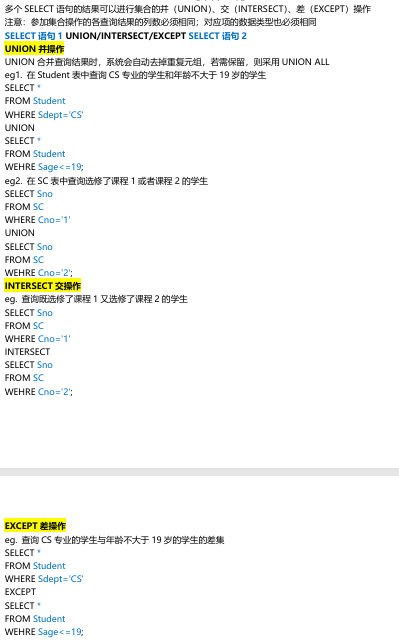
基于派生表的查询

INSERT
插入元组
INSERT
INTO表名(列名1,列名n)
VALUES(常量1,常量n); #字符串常量要用单引号()括起来假设现有TAB1表,共有C1到C4四列,其中C4列是字符串常量 situation1.明确给出新增元组要在哪些属性上赋值(插入数据包含全部属性列)
INSERT
INTO TAB1 (C1, C2, C3,C4)
VALUES(1,2,3,'4");situation2.仅指出在TAB1表上插入元组(插入数据包含全部属性列)
INSERT INTOTAB1 VALUES(1,2,3,'4");//这种情况表示要在TAB1表全部各列赋值,且插入数据的顺序必须和列的顺序对应
situation3.明确给出新增元组要在哪些属性列上赋值(插入数据不包含全部属性列)
INSERT
INTO TAB1 (C1, C2, C3)
VALUES(1,2,3);# 这种情况下,C4列会被赋为NULL注意:当表定义说明了NOT NULL时,不赋值会出错
插入子查询结果
INSERT
INTO表名 (属性列1,属性列 n)
子查询://子查询嵌套在INSERT语句中生成要插入的批量数据
eg.假设现有TAB1表(如上),并按C1列分组求C2列的平均值,并存入TAB2表(其中TAB2表的C1列存放C1,avg_C2列存放C2列的均值)
INSERT
INTO TAB2 (C1, avg_C2)
SELECT C1,AVG(C2)
FROM TAB1
GROUP BY C1;UPDATE
UPDATE 表名
SET列名1=表达式1,列名n=表达式n
WHERE条件://修改指定表中满足WHERE子句条件的元组;若省略WHERE,表示要修改表中的所有元组
situation1.修改某一个元组的值
UPDATE TAB1
SET C4='0'
WHERE C1=1;situation2.修改多个元组的值
UPDATE TAB1
SET C3 = C3+1;situation3.带子查询的修改语句
UPDATE TAB1
SET C4='0'
WHERE C1 IN
(SELECT C1
FROM TAB2
WHERE avg_C2=2;DELETE
DELETE
FROM 表名
WHERE条件://删除指定表中满足WHERE子句条件的元组;若省略WHERE,表示要删除表中的所有元组
注意:DELETE语句删除的是表中的数据,并不是表的定义,表的定义仍在数据字典当中
situation1.删除某一个元组的值
DELETE
FROM TAB1
WHERE C1=1;situation2.删除多个元组的值
DELETE
FROM TAB1; #TAB1将变成空表situation3.带子查询的删除语包
DELETE
FROM TAB1
WHERE C1 IN
(SELECT C1
FROM TAB2
WHERE avg_C2=2);VIEW视图
定义视图 CREATE VIEW
CREATEVIEW视图名(列名1,列名n)//若省略列名,则该视图子查询中SELECT的目标列字段组成
AS子查询
WITH CHECK OPTION;//若添加该句,则表示对视图进行增删改时要满足子查询中的条件表达式
在以下情况中必须明确指定组成视图的列名:
- 某个目标列不是单纯的列名,而是聚集函数或列表达式
- 多表连接时选出了几个同名列作为视图的字段
- 需要在视图中为某个列启用新的更合适的名字
行列子集视图:由单个基本表导出,仅去掉了基本表的某些行和某些列,但保留了主码
若某些视图是建立在另一个表的全部属性列上的,即视图与基本表的各列是一一对应的。那么当修改基本表的结构时,基本表和视图的映像关系会被破坏。这种情况最好在修改基本表后删除该视图,然后重建该视图
eg1.建立TAB1的视图
CREATE VIEW V_TAB1
AS
SELECT C1,C2,C3,C4eg2.建立C4为4时TAB1的视图,并保证以后每次增删改时都要满足C4为4的条件
CREATE VIEWV_TAB2
AS
SELECT C1,C2,C3,C4
FROM TAB1
WHERE C4='4'
WITH CHECK OPTION;eg3.建立在一个或多个已定义号的视图上
CREATE VIEW V_TAB3
AS
SELECT C1, C2,C3
FROM V_TAB1
WHERE C2=2;eg4.为减少冗余数据,定义基本表时一般只存放基本数据。当需要使用计算得出的派生数据时,可以设置在视图中的派生属性列上,也称为虚拟列。带虚拟列的视图也称为带表达式的视图
CREATE VIEW V_TAB4(C1, new_C2)
AS
SELECT C1,10+C2
FROM TAB1;eg5.分组视图:带有聚集函数和GROUPBY子句
CREATE VIEWV_TAB5(C1,aVg_C2)
AS
SELECT C1,AVG(C2)
FROM TAB1
GROUP BY C1;删除视图 DROP VIEW
DROPVIEW视图名CASCADE;//若使用CASCADE级联删除语句,则将把该视图导出的所有视图一并删除
DROP VIEW V_TAB2;DROP VIEW V_TAB1 CASCADE;# 由VTAB1导出的V_TAB3也一并删除空值
